
3. Works and versions#
Many of Trove’s categories contain things called ‘works’. Works are not individual items, they’re containers for related ‘versions’ (now called ‘editions’ in the web interface). Trove has a set of rules for grouping versions into works, but the logic is not always apparent to end users. As a result, it’s easy to get confused. This section tries to explain the idea behind work groupings, as well as documenting some of the inconsistencies and errors. The grouping of versions into works has important implications for the research use of Trove’s metadata.
3.1. Grouping versions into works#
The idea is simple enough – bring all the versions of a publication together under a single heading to simplify a user’s search results. Instead of having to wade through a long list of near-identical entries, a user can quickly focus in on a title of interest, and drill down to find a specific version at a specific library. This idea is based on the Functional Requirements for Bibliographic Records (FRBR). The FRBR data model describes four entities: ‘work’, ‘expression’, ‘manifestation’, and ‘item’:
Work is defined as the intellectual or artistic content of a distinct creation. It refers to a very abstract idea of a creation e.g. Shakespeare’s Romeo and Juliet and not a specific expression.
Expression is the intellectual or artistic realization of a work. The realization may take the form of text, sound, image, object, movement, etc., or any combination of such forms.
Manifestation is the embodiment of an expression of a work. For example a particular edition of a book or a specific music recording.
Item is a single exemplar of a manifestation. Cataloguing is generally done, based on an item directly available to a cataloguer
Trove uses a simplified FRBR model with ‘works’ and ‘versions’. Trove’s versions combine aspects of FRBR’s ‘expression’ and ‘manifestation’.[Cathro and Collier, 2010]
To create the work groupings, Trove inspects each metadata record, comparing identifiers like ISBNs, as well as fields such as title and creator. Points are assigned for matches between records, and if the points total exceeds a threshold score, the records are grouped as versions within a work.
A second round of grouping looks at all the versions in a work to find and cluster closely-matched records that describe the same edition. For example a work might contain three records with the same title and author. But if two of the records also have identical publication details, they’ll probably be grouped as a single version. As a result, the work will end up with two versions, though one of the versions will contain two records:
work
-- versions (match – same title and author)
-- version 1
-- records
-- record 1
-- version 2
-- records (closer match – same publication details)
-- record 2
-- record 3
Each version record contains its own set of metadata. As records are derived from different sources, this metadata can vary in significant ways. The grouping process aggregates this metadata upwards to populate fields in the work and version containers. For example, title and contributor fields are added to the work-level record, with values derived from the version records. As versions can have different publication dates, the work’s issued field will often display a date range encompassing the dates of all grouped versions.
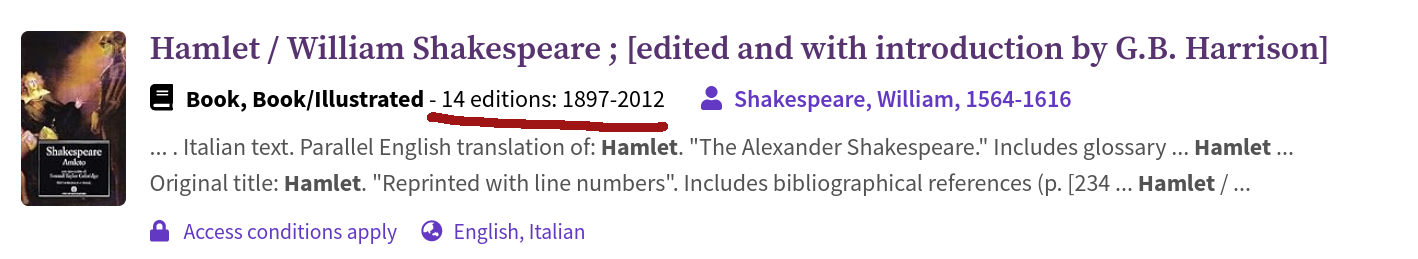
Fig. 3.1 Display of work record in search results. The date range encompasses the dates of the work versions.#
Searches using either Trove’s web interface or the API will return work-level records. This means your search results will display the aggregated metadata generated by the grouping process. To view individual version records, you need to navigate down the hierarchy from the work level. In the web interface, versions are displayed on a work’s page as a list of ‘editions’ that can be filtered by format, language, and date. If you’re using the API, version details are not included by default – to see them, you need to set the include parameter to workversions. ==Link here to more API info in accessing data==
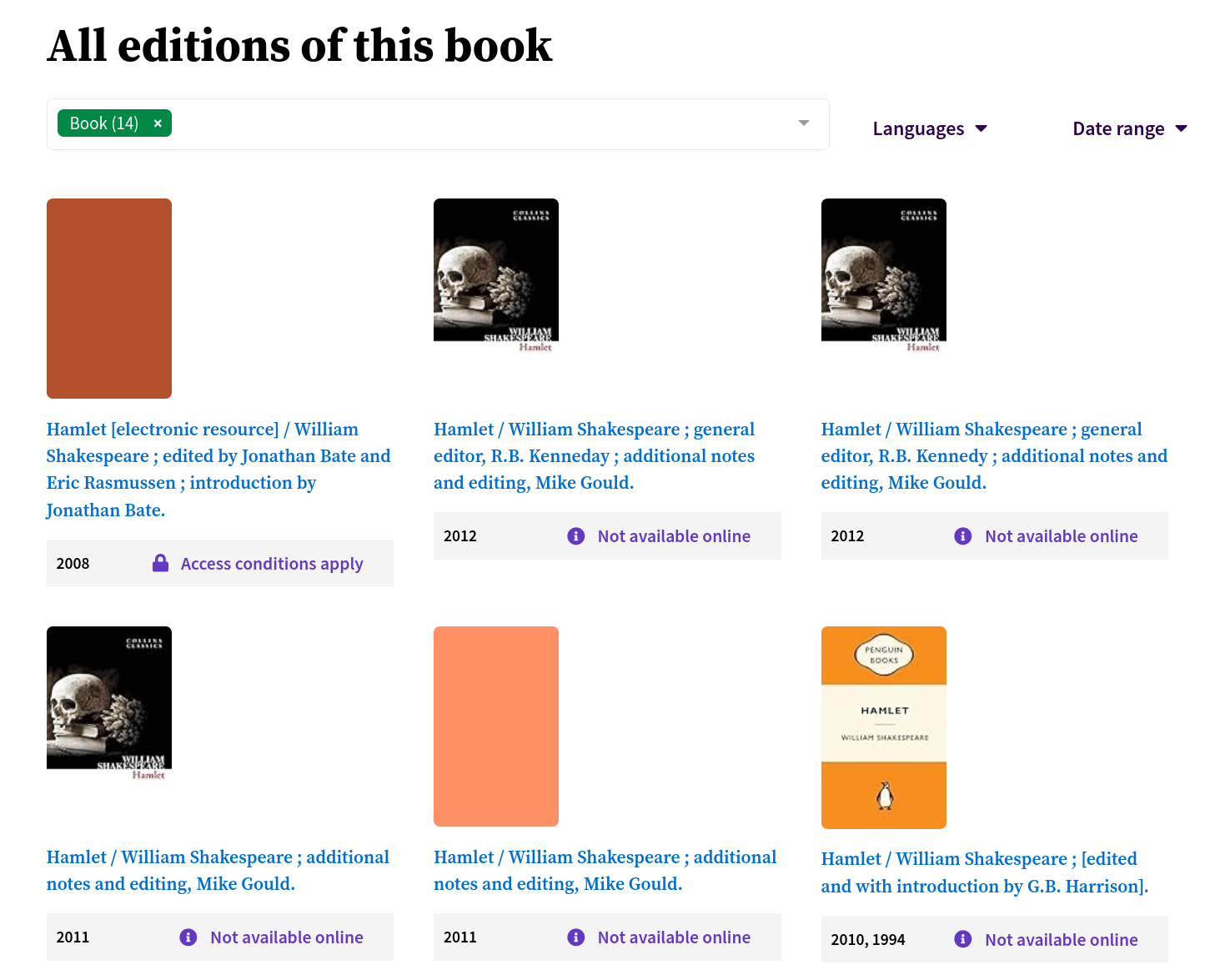
Fig. 3.2 Display of editions (versions) on a work page. You can filter by type, language, and date.#
KEY POINTS
3.2. Muddy metadata#
Grouping versions into works promises users cleaner search results, but the reality is more complex and confusing. You don’t have to look around too much to find problems with the way Trove’s groupings are implemented.
This ‘work’ is titled The Wiggles and has 31 ‘editions’ listed in Trove. The problem is that most of those editions are actually different works, a mix of books, CDs, and DVDs. Presumably the grouping algorithm is connecting them because of the appearance of ‘The Wiggles’ somewhere in the title, but it’s hard to know for sure as the scoring mechanism isn’t publicly available.
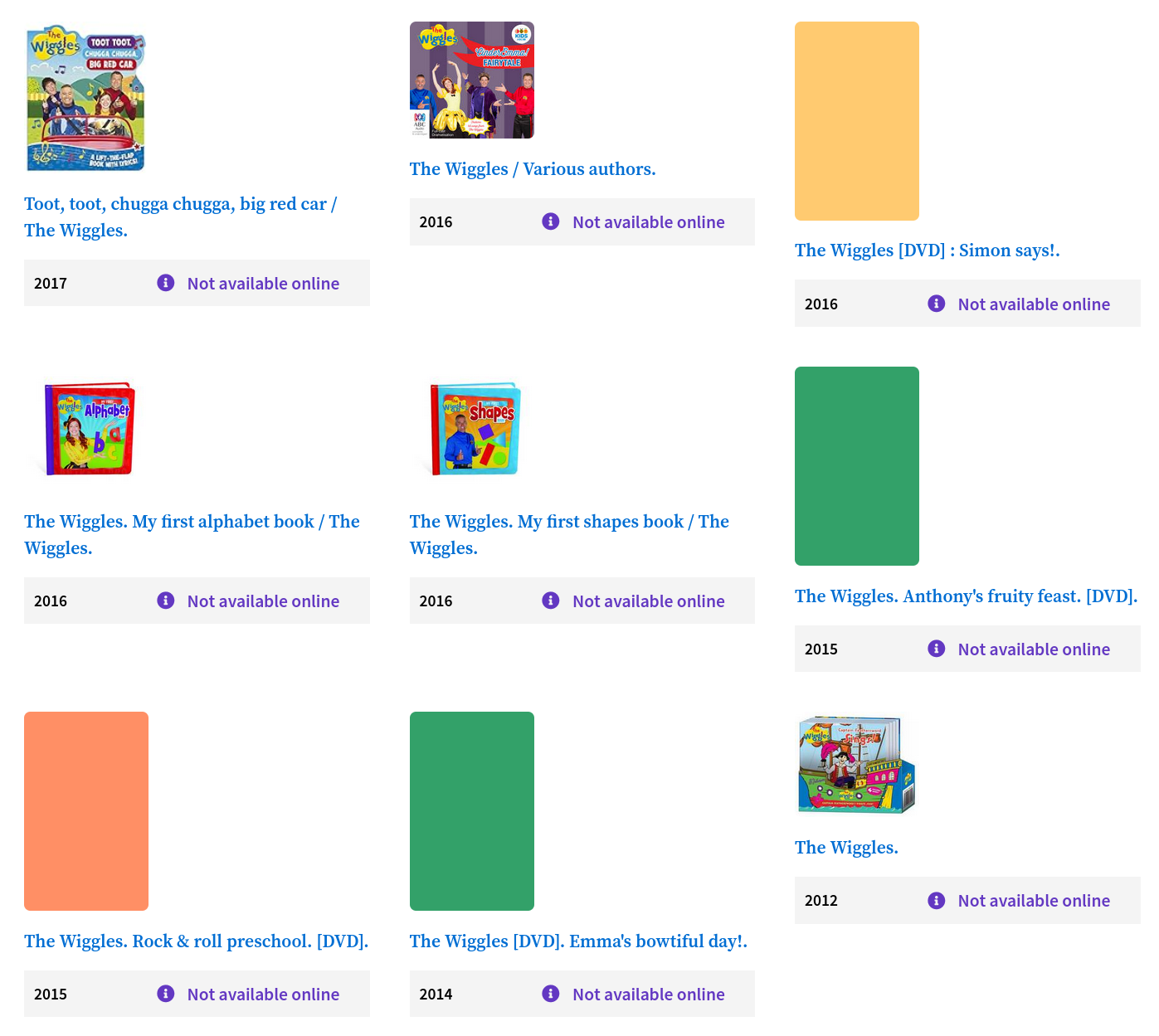
Fig. 3.3 These different Wiggles publications are grouped as a single ‘work’.#
Perhaps this is an extreme example, but grouping errors are common. In the Hamlet example I used above, the work record was titled ‘Hamlet / William Shakespeare ; [edited and with introduction by G.B. Harrison]’. But the grouped versions include introductions and commentaries by a range of different scholars, not just G.B. Harrison. Perhaps the algorithm is working as expected – they’re all copies of Hamlet after all. But if you were searching for a copy of Hamlet with notes by Mike Gould, would you think to click on the G.B. Harrison result?
Search operates across all the versions in a work, so any variations in titles and authors will be indexed as expected. They’re all in there somewhere. But search results deliver work-level records, the details of which might not reflect the version that matched your query. At best this might cause some momentary confusion before you click through to the work page, at worst you might simply ignore the result as some sort of error. Grouping by work simplifies the search experience in Trove by reducing the number of similar results. But this grouping can obscure important differences between versions, making it harder to interpret the results returned.
Grouping also has an impact on other navigation components, blurring the boundaries of Trove’s categories and facets. For example, books can turn up in the Music, Audio, & Video category because they’ve been grouped with an audio recording. This can improve discoverability across categories, but it can also be confusing when your music search returns a list of books. The usefulness of facets can be compromised by large, diverse groupings. For example, if you use the decade and year facets to try to find a publication from a particular date, your results will include any work grouping whose date range encompasses your period of interest.
User testing on early versions of Trove showed that the ‘core conceptual model of FRBR’ was ‘largely not understood’.[Holley, 2011] Over the years there have been changes to the grouping algorithm, and to the way versions are presented in the web interface, but it’s still a challenge for users to understand what’s going on. Perhaps this is an inevitable result of trying to bolt a FRBR-ish system on top of an aggregated collection – it’s hard to make effective and consistent rules when merging metadata from multiple sources.
3.3. Not the same#
The challenges are magnified when working with resources that don’t come from standard library systems. For example, Trove indexes speeches and interviews by Australian Prime Ministers from the PM Transcripts site. As a result, you can find transcripts of 106 different press conferences by John Howard grouped as a single work!

Fig. 3.4 Too many John Howards#
Trove indexes both the metadata and full text of the press releases (or at least the first 30,000 characters). That’s awesome, because your Trove search actually looks inside the press releases. But if your search returns this collection of press releases as a single ‘work’, how do you find which of the 106 documents matched your query? You can’t. You have to inspect each press release individually on the PM Transcripts site. An opportunity for rich, deep discovery of aggregated resources is foiled by the grouping algorithm.
There are a number of other aggregated collections that contribute different full text content under recurring titles. For example the Parliamentary Library’s database of press releases, and ABC Radio National.
Researchers need to factor both the FRBR concept, and Trove’s implementation of it, into their search strategies – recognising that there will be errors and inconsistencies in the way versions are grouped together.
3.4. Digitised works#
You’d expect there to be fewer problems with work records related to Trove’s own digitised content, but there’s actually a few additional oddities. These stem from the use of works and versions to describe collections – the ‘work’ is used as a collection container and each ‘version’ is a separate item in that collection. It’s really not very FRBR-ish at all, and perhaps reflects the fact that Trove is severely limited in its ability to represent hierarchical data structures.
This ‘work’ is actually a collection of ephemera relating to the National Anti-Sweating League of Victoria. There are nine items in this collection and they’re all quite different – they’re not versions or editions of a single work.