
6. Interfaces#
On this page
For most users, Trove is defined by its web interface – by the screens, buttons, boxes, links, and lists you interact with as you navigate around the site. This Guide focuses on getting and using the data that sits behind the web interface, but, in some cases, access to data is constrained by the design and functioning of the website. It’s therefore useful to think about the different components of the web interface and how they fit together.
6.1. Trove welcome, news, and help pages#
The Trove home page, and the various news and documentation pages connected to it, are delivered through a content management system. New articles are added regularly. You can catch up on what’s been posted recently on the News page. Unfortunately there’s no functional RSS feed.
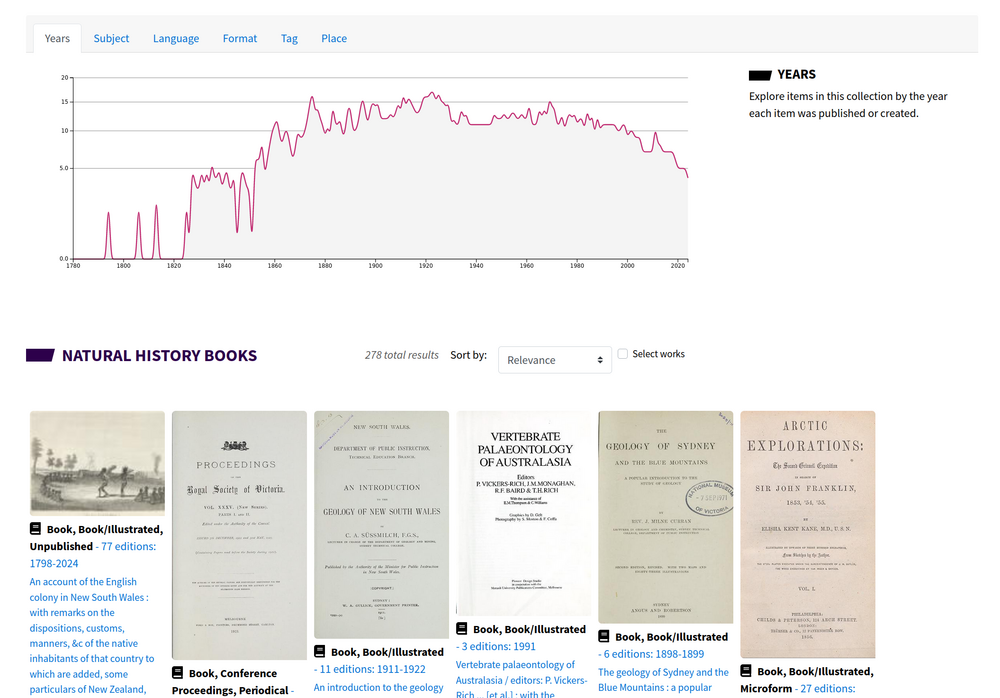
Fig. 6.1 A collection feature on Natural History Books
https://trove.nla.gov.au/collection/BHL/biodiversity/explore#
Of particular interest are the Collection Features which present curated subsets of Trove resources. These include some basic visualisations, and an option to search within the collection subset. However, there doesn’t seem to be any way of downloading information about the complete set of items in a subset. The usual Bulk Download option isn’t available, and the main Trove API doesn’t know anything about these ‘collections’.
Some useful links are hidden in unexpected places:
the Newspapers & Gazettes browse interface is linked from the Explore tab
the thematic collection of web sites selected for preservation is linked from the Categories tab
API documentation can be found under the About > Create something menu item
6.2. Search interface#
The search application is at the heart of Trove, giving users a single entry point to a range of different systems and formats. See the Trove help system for an introduction, and the Understanding search section of this Guide for hints and tricks.
Trove’s search interface includes a number of different components.
‘Simple’ search box#

Fig. 6.2 Trove’s simple search box#
Simple in design, but powerful in function – see ‘Simple’ search options for information on constructing complex queries.
‘Advanced’ search form#
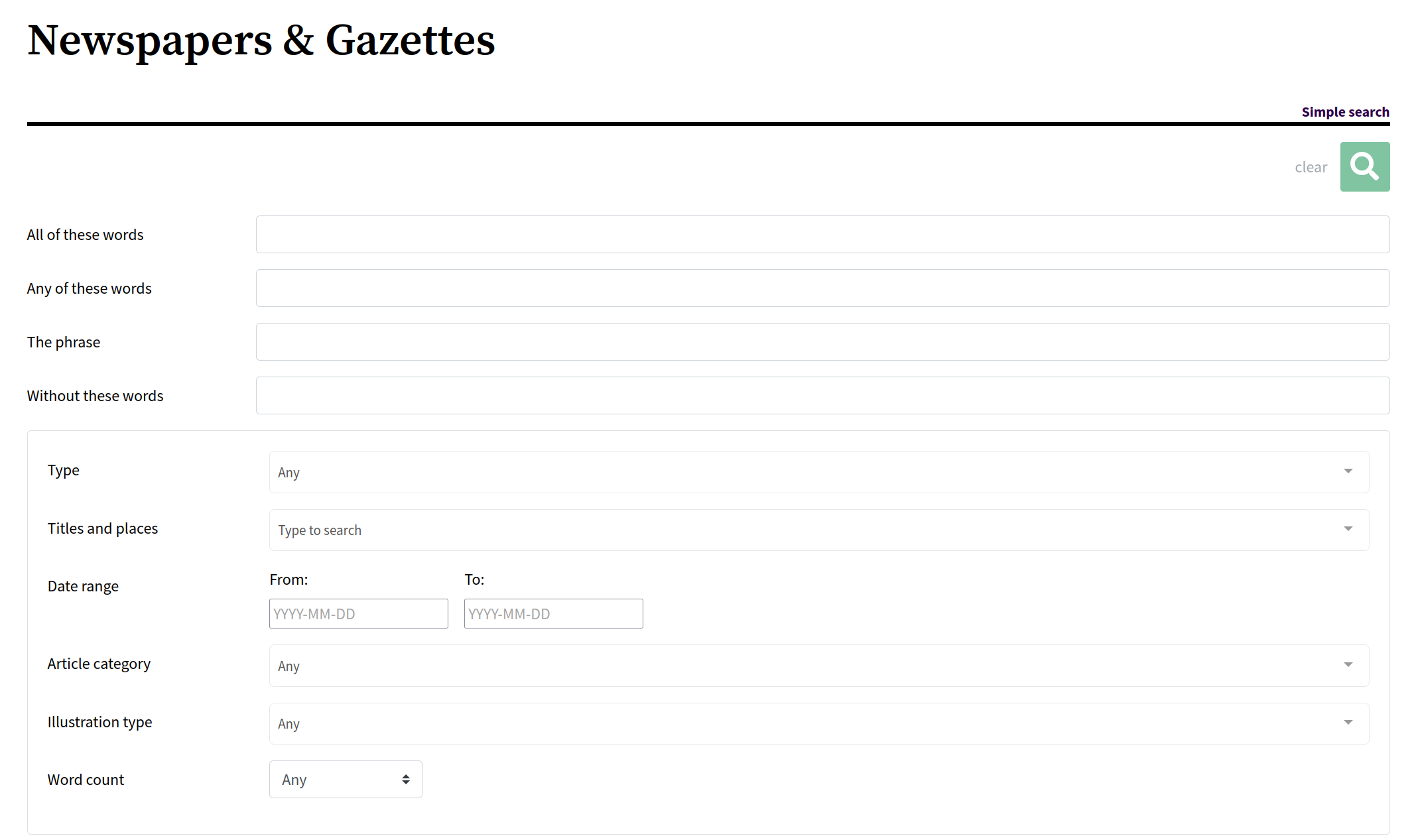
Fig. 6.3 The advanced search form for digitised newspapers#
Advanced search doesn’t really add any search options (except in the websites category), but it does layer a structured interface over the standard query options. Each category has it’s own version of the advanced search form with slightly different fields.
Search results summary#
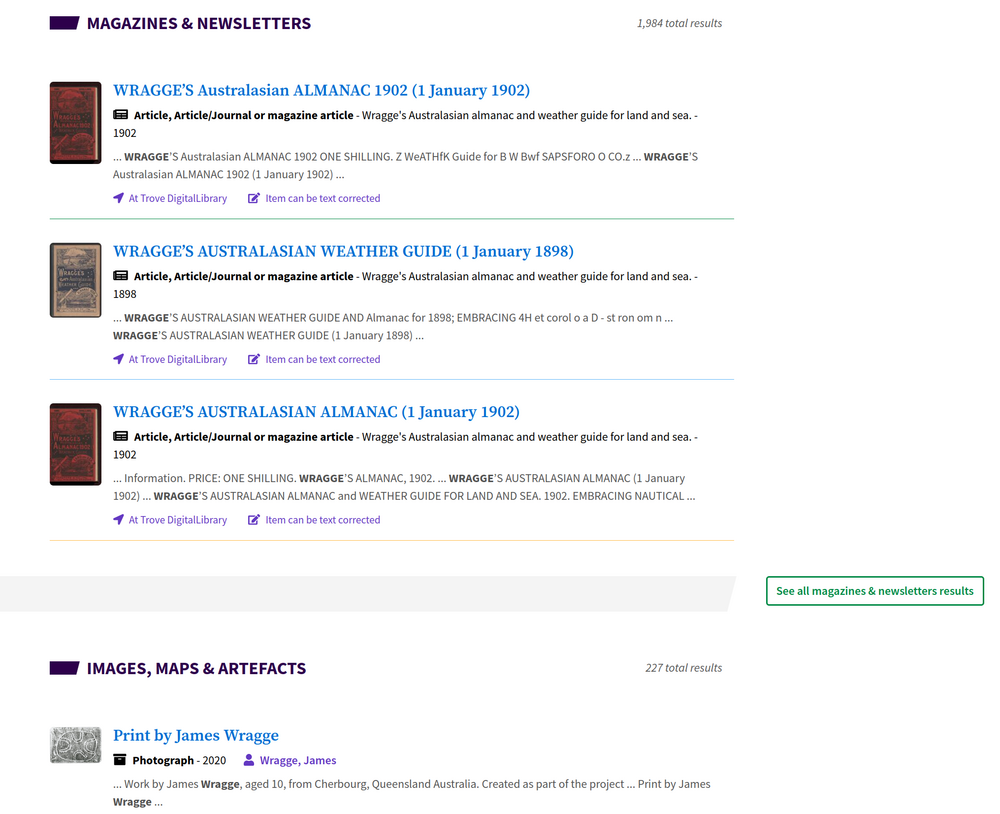
Fig. 6.4 An example of the results presented by the search summary screen#
The search results summary page provides a single page overview of results across all categories (except websites). It displays the total number of results in each category, the three top results, and a link to view the complete set of results.
Search results#
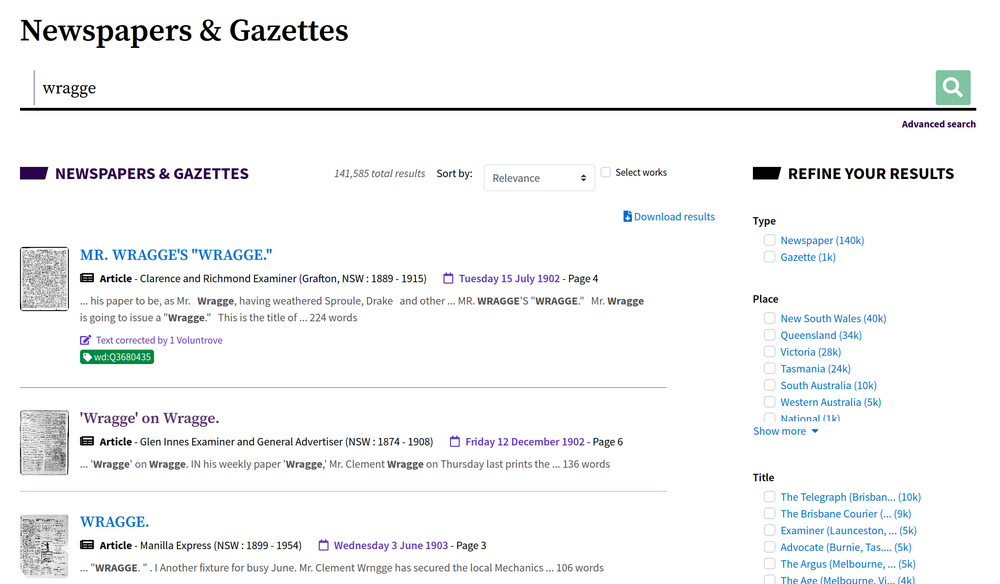
Fig. 6.5 An example of search results in the newspapers category#
The search results page lists twenty results at a time (more with a little url hacking), and most categories provide options to sort and filter the results. The Images, Maps & Artefacts category displays results in a grid rather than a list.
6.3. Work and version records#
See Trove records in the Trove help documentation for an introduction.
Works are the basic units of description for the categories that contain aggregated content:
Books & Libraries
Diaries, Letters & Archives
Images, Maps & Artefacts
Magazines & Newsletters
Music, Audio & Video
Research & Reports
Trove tries to group all the versions of a particular resource into a single work. If a work contains multiple versions (called ‘Editions’ in the web interface), then the default work view will provide a list of available versions to select from. If there’s only one version then that version record will be displayed automatically.
Work#
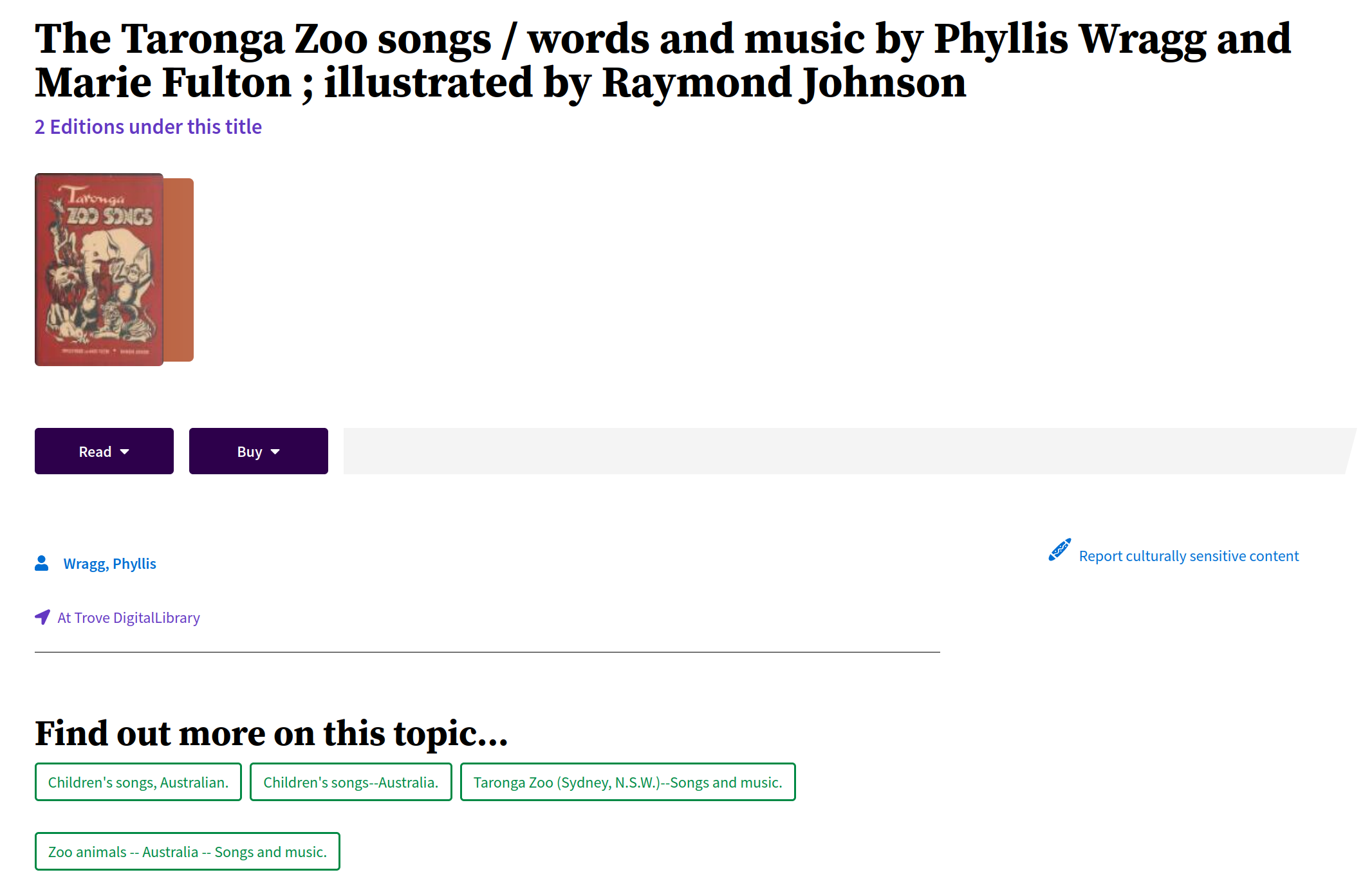
Fig. 6.6 A work record containing multiple versions
https://trove.nla.gov.au/work/34731475#
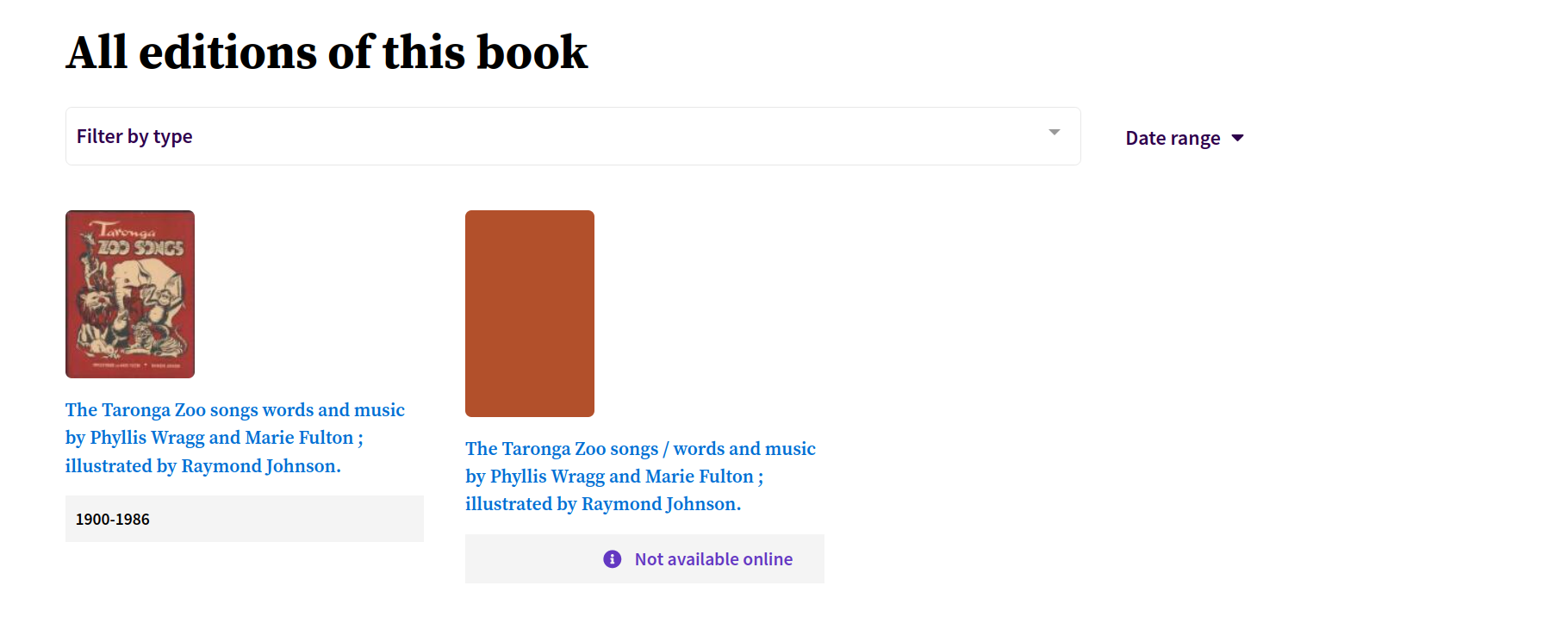
Fig. 6.7 Select a version of this work from the list
https://trove.nla.gov.au/work/34731475#
Version#
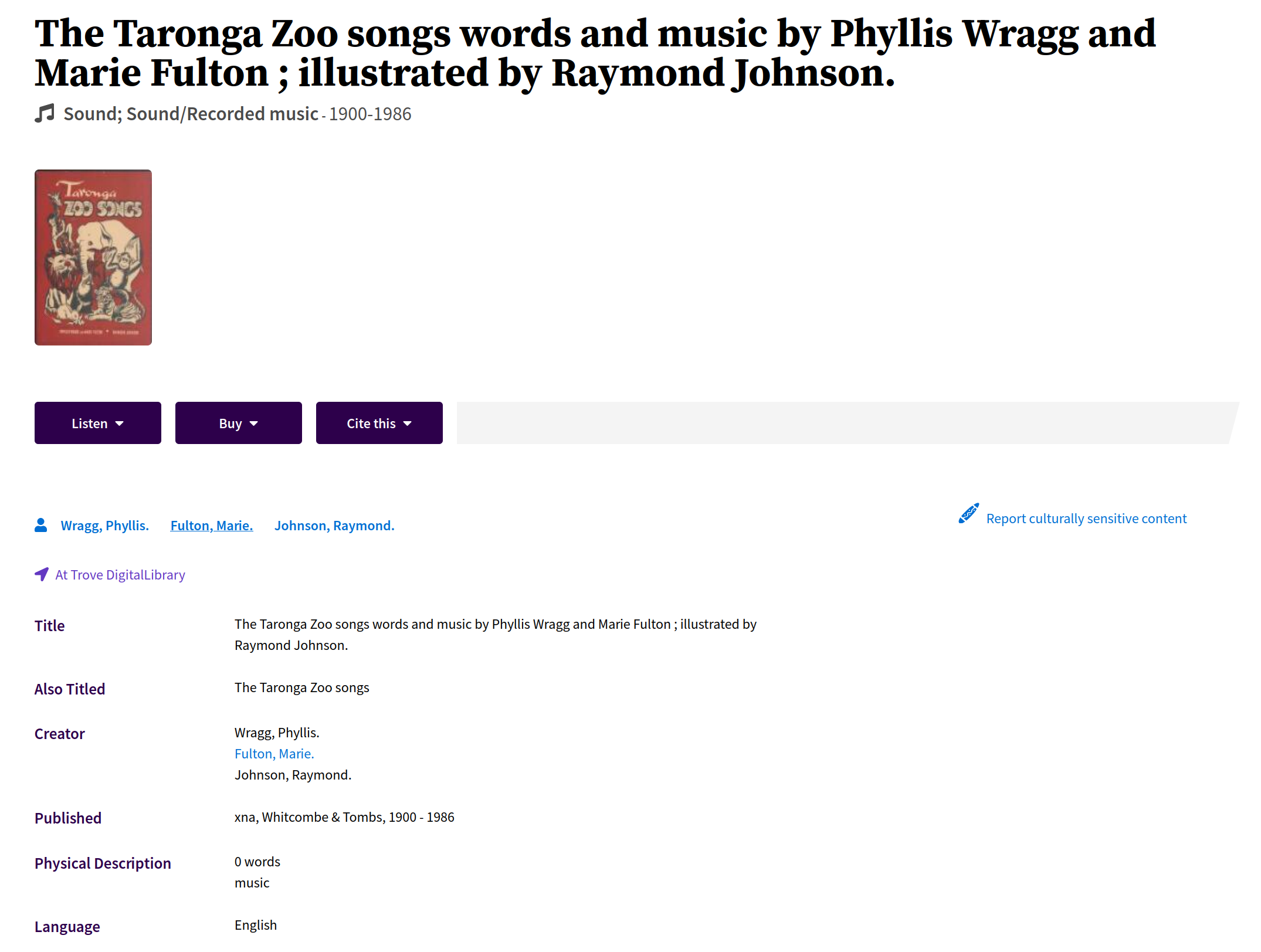
Fig. 6.8 A single version record
https://trove.nla.gov.au/work/34731475/version/264818091#
6.4. Newspapers#
See Newspaper viewer in the Trove help documentation for an introduction.
Browse interface#
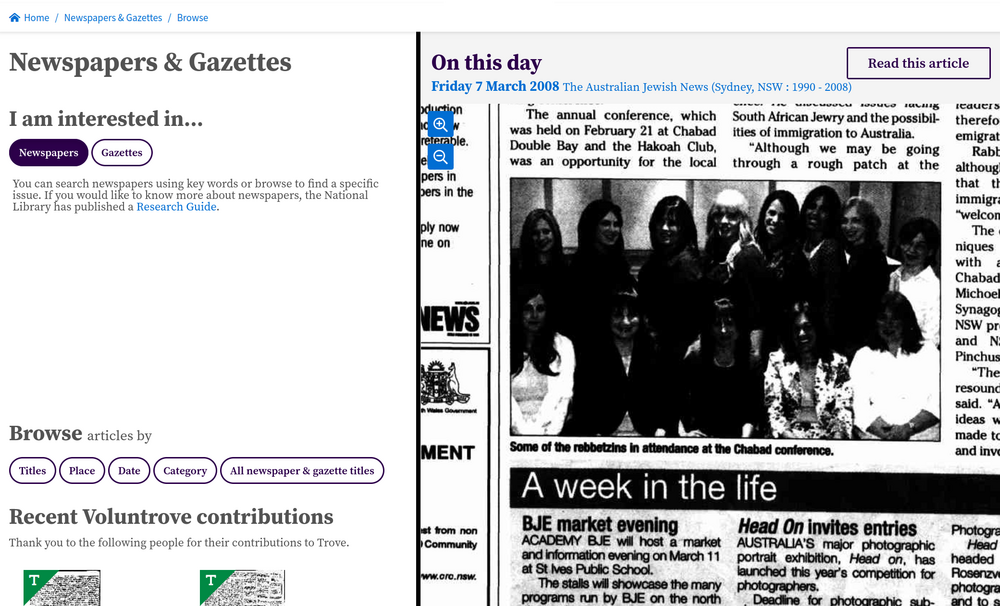
Fig. 6.9 The Newspapers & Gazettes browse interface
https://trove.nla.gov.au/newspaper/#
Title browser#
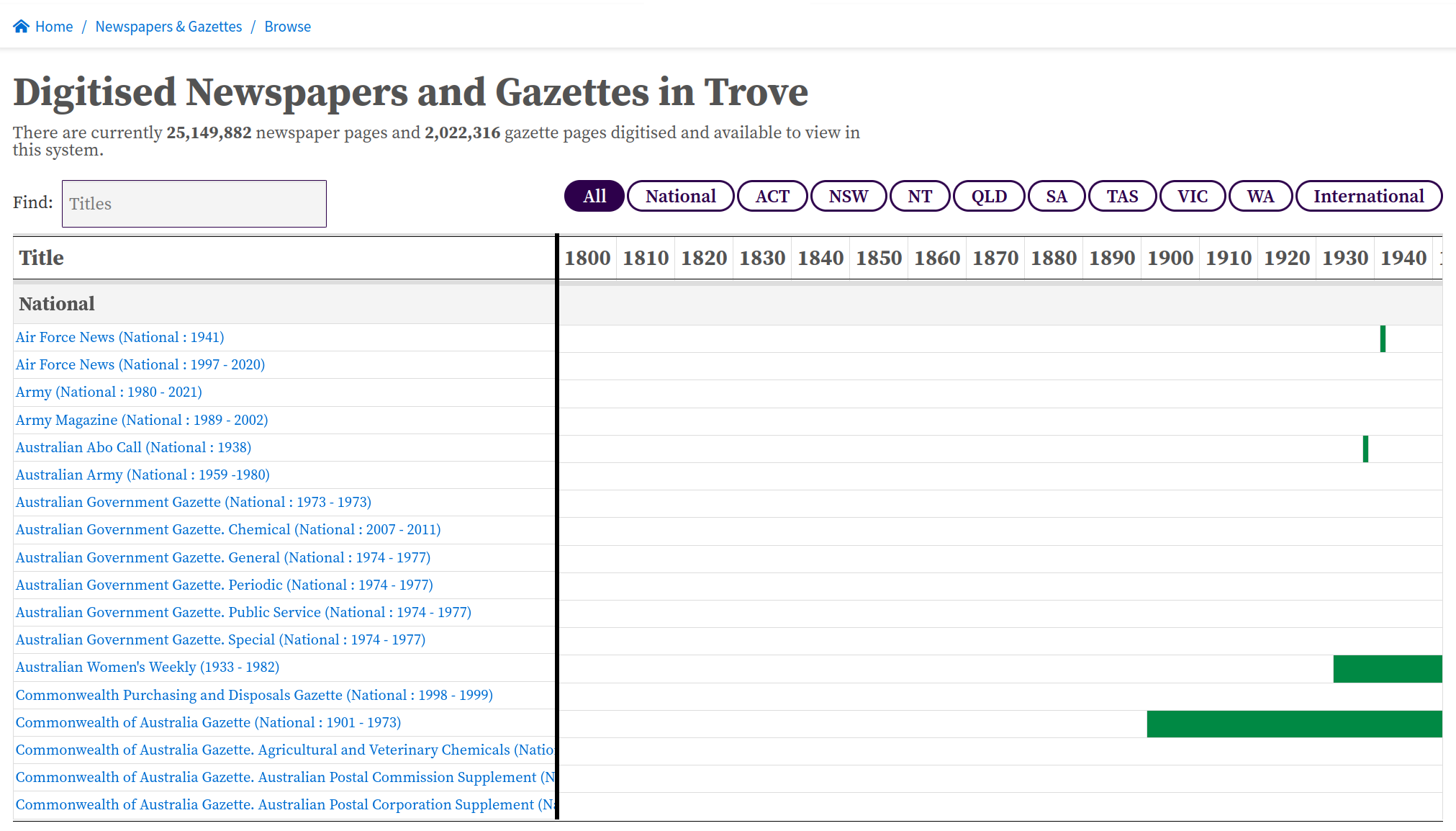
Fig. 6.10 Browse a list of newspaper titles
https://trove.nla.gov.au/newspaper/about#
Title details#
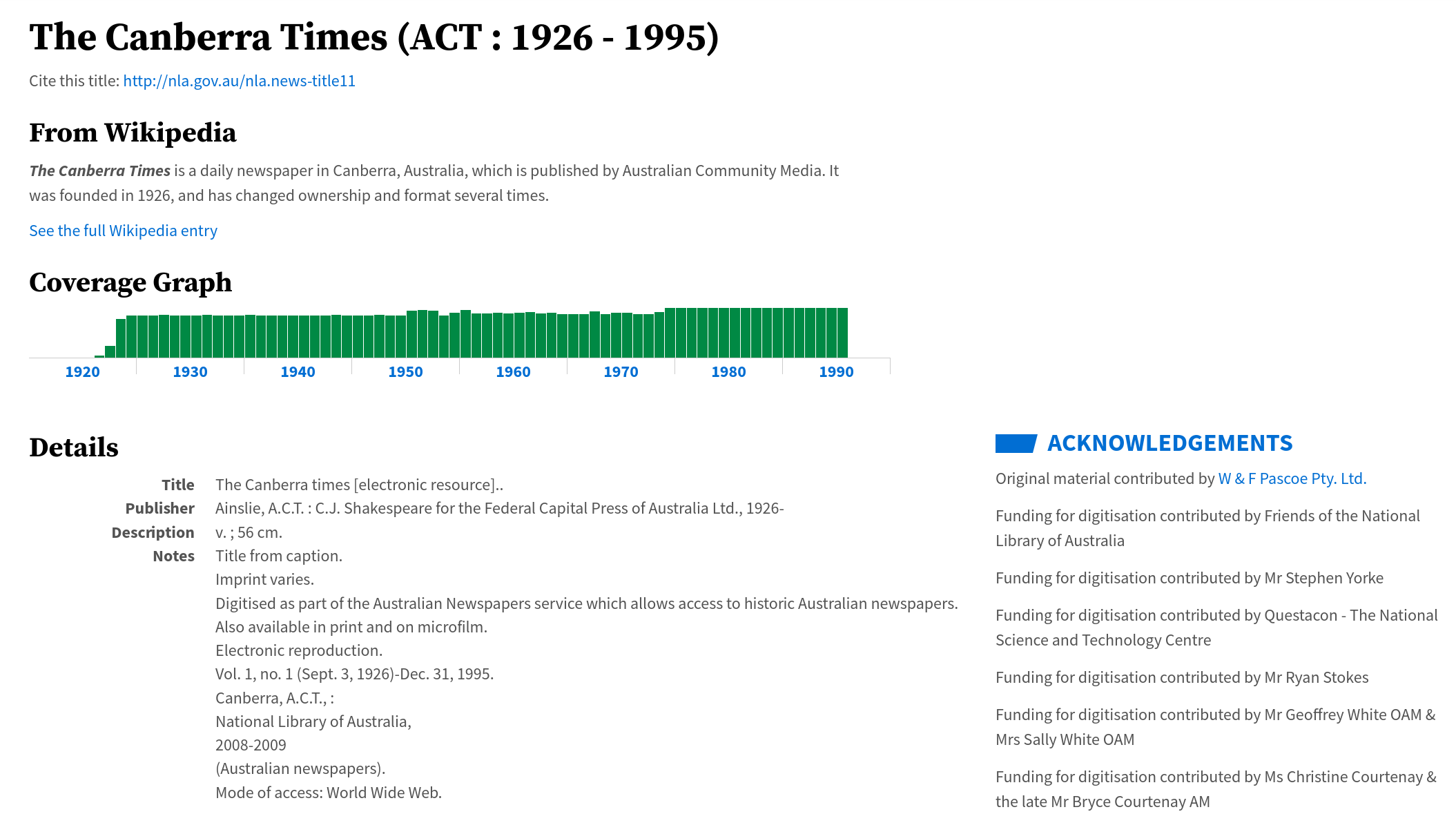
Fig. 6.11 View the details of a single title, in this case, the Canberra Times
https://nla.gov.au/nla.news-title11#
Page viewer#
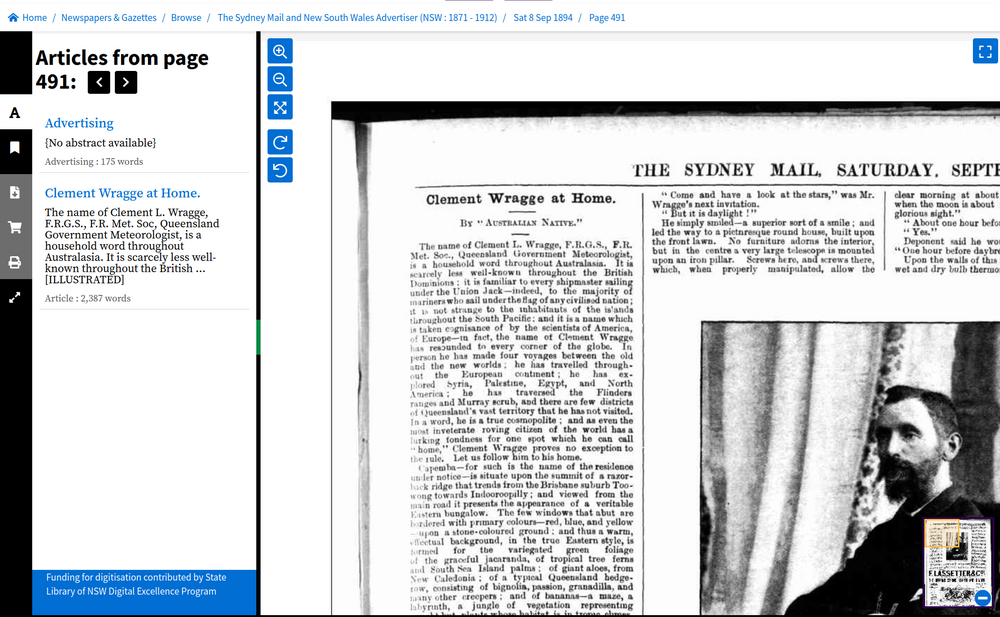
Fig. 6.12 View details of all the articles on a single page
https://nla.gov.au/nla.news-page16636766#
Article viewer#
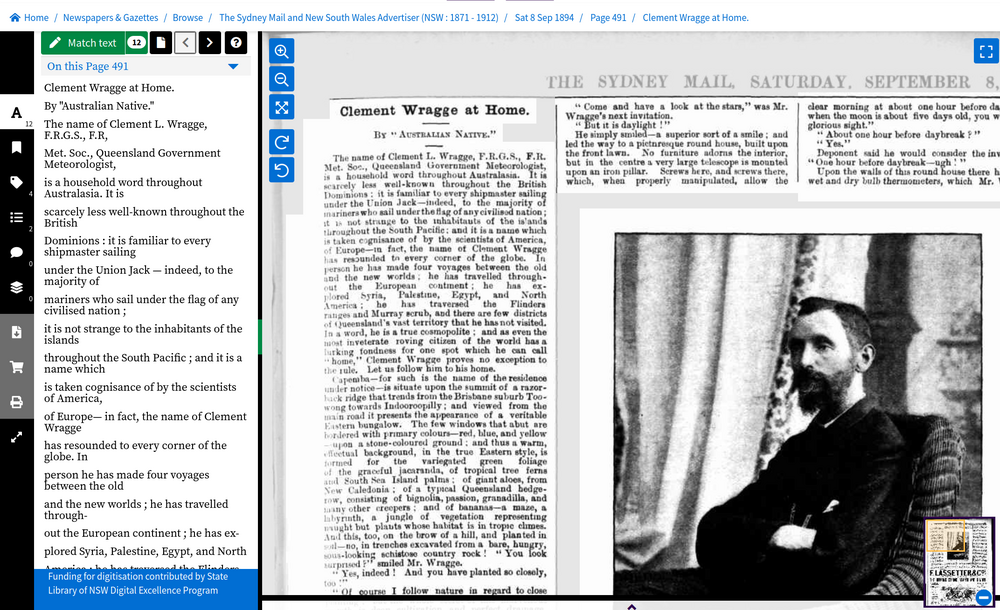
Fig. 6.13 View a single article
https://nla.gov.au/nla.news-article162833980#
6.5. Digitised content viewers#
There are different viewers for different types of digitised content. Most of the viewers share a basic design and set of functions, however, the audio player is quite distinct.
You’re most likely to arrive at one of the digitised content viewers from a link in a work record. However, the viewers don’t include links back to work records in Trove. Instead they usually include links to the NLA’s catalogue. If you want to find the corresponding work record (or records) in Trove, you’ll need to construct a search using the digital object identifier.
The amount of metadata presented in the digitised content viewers varies, and it doesn’t always match what’s in the work record. Interestingly, the HTML of the viewers embeds additional metadata as a JSON object. You can extract this data and use it to do things like downloading text, images, and PDFs.
Collection viewer#
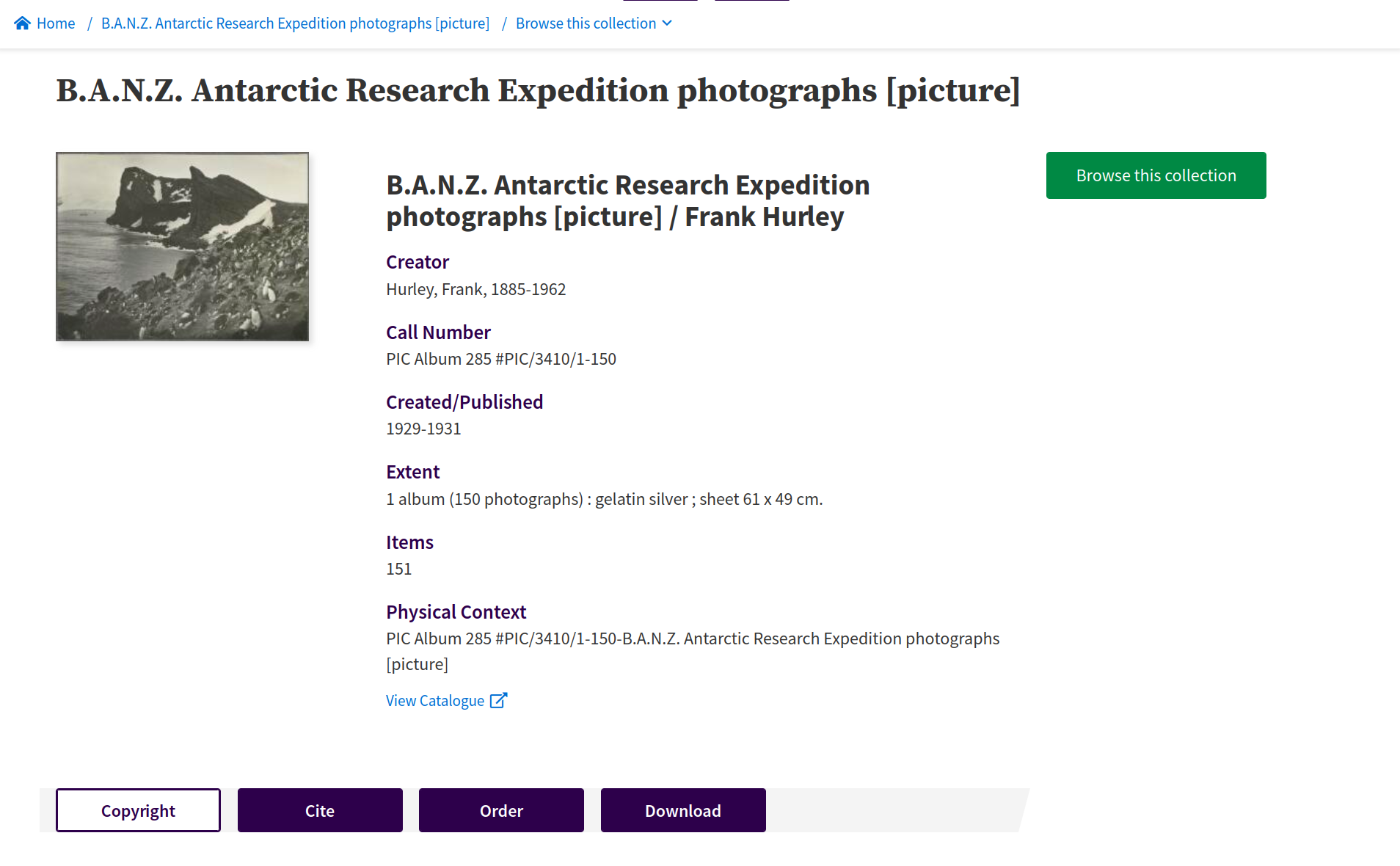
Fig. 6.14 View a collection of digitised items https://nla.gov.au/nla.obj-141170265#
The Browse this collection button opens a modal window that lets you navigate through the items in the collection. This list is generated by an internal web request that returns an HTML fragment. You can use these fragments to assemble machine-readable data about the items in a collection.
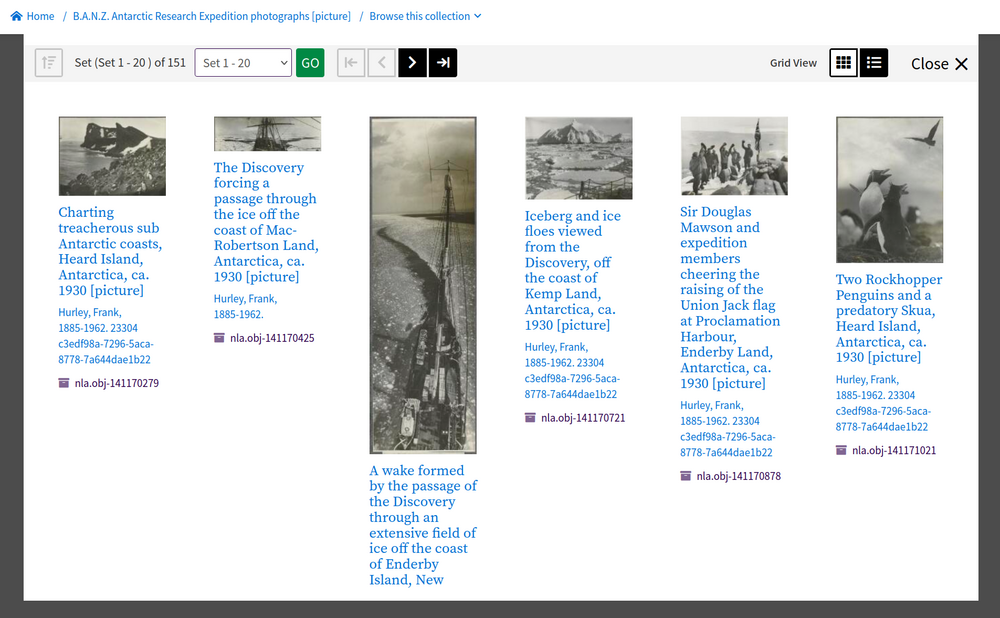
Fig. 6.15 View a list of items within a digital collection https://nla.gov.au/nla.obj-141170265#
Digital collections can contain a range of formats. For example they can describe multi-volume books, list all the issues in a periodical, display all the photographs in an album, or describe a collection of ephemera. They can even contain other collections.
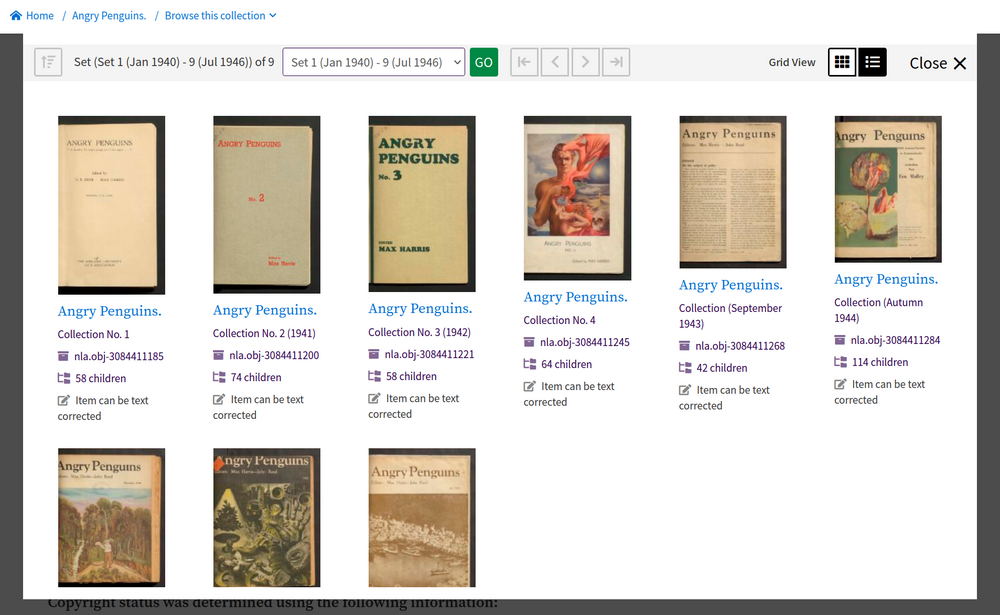
Fig. 6.16 View a list of the issues available from a digitised periodical
http://nla.gov.au/nla.obj-52986893#
Book and journal viewer#
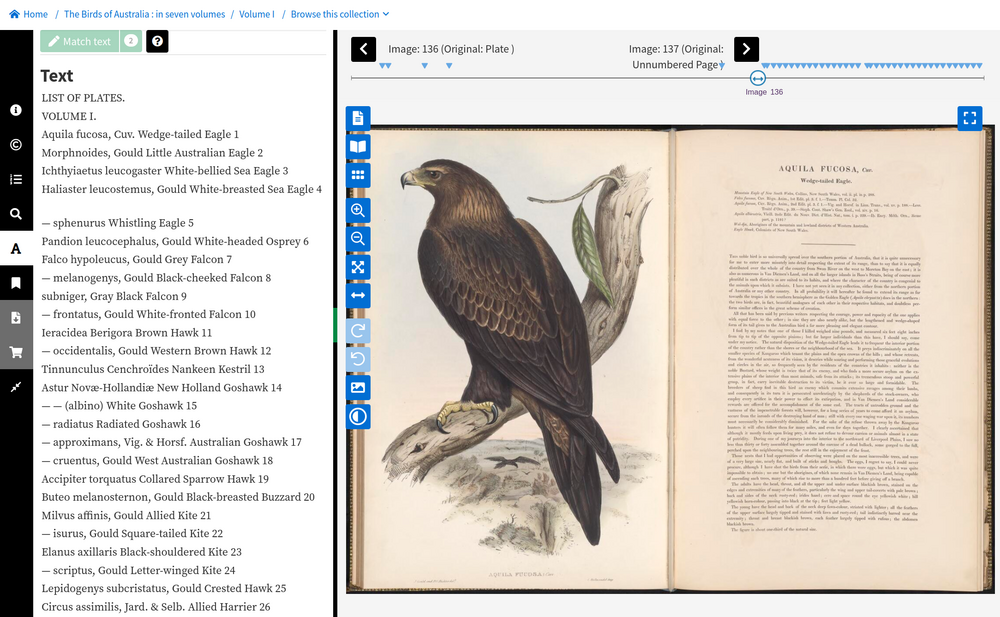
Fig. 6.17 View a digitised book
https://nla.gov.au/nla.obj-3071128587#
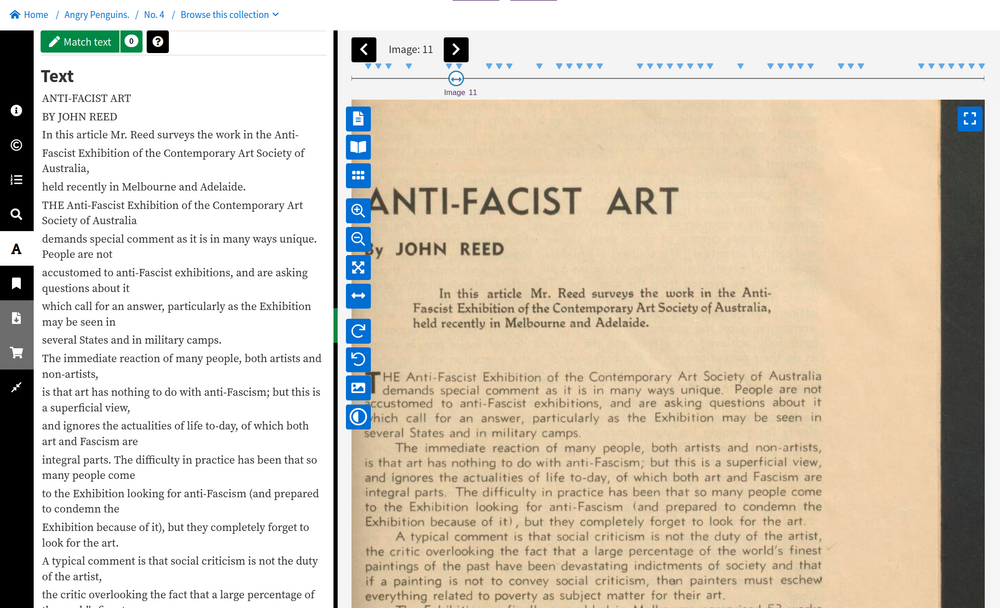
Fig. 6.18 View an issue from a digitised periodical
https://nla.gov.au/nla.obj-3084411245#
Image viewer#
See Image viewer in the Trove help documentation for an introduction.
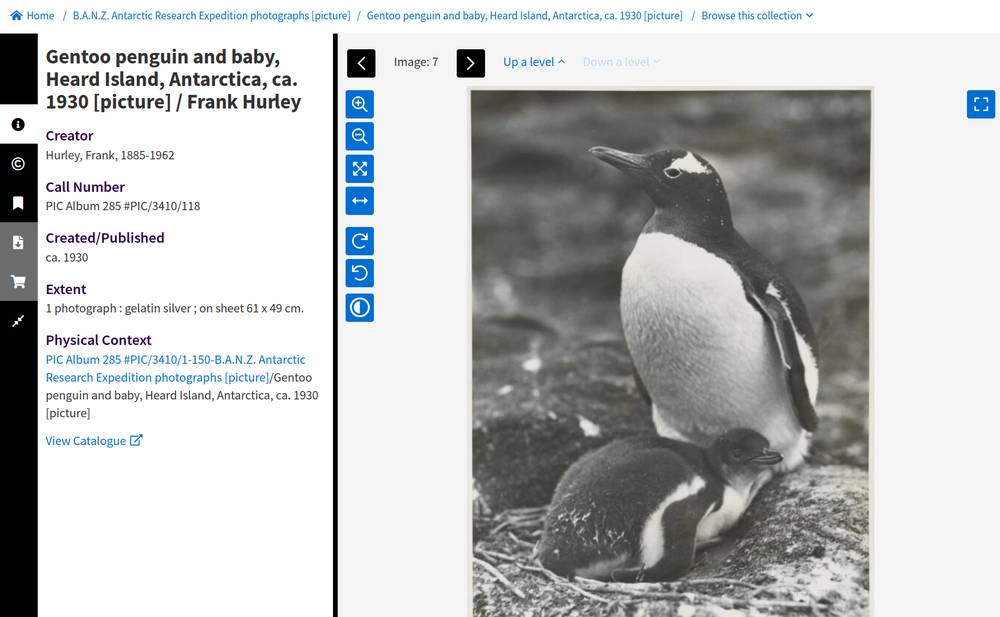
Fig. 6.19 View a digitised image
https://nla.gov.au/nla.obj-141171324#
Map viewer#
See Map viewer in the Trove help documentation for an introduction.
Some map series have a clickable index to enable you to navigate around the collection.
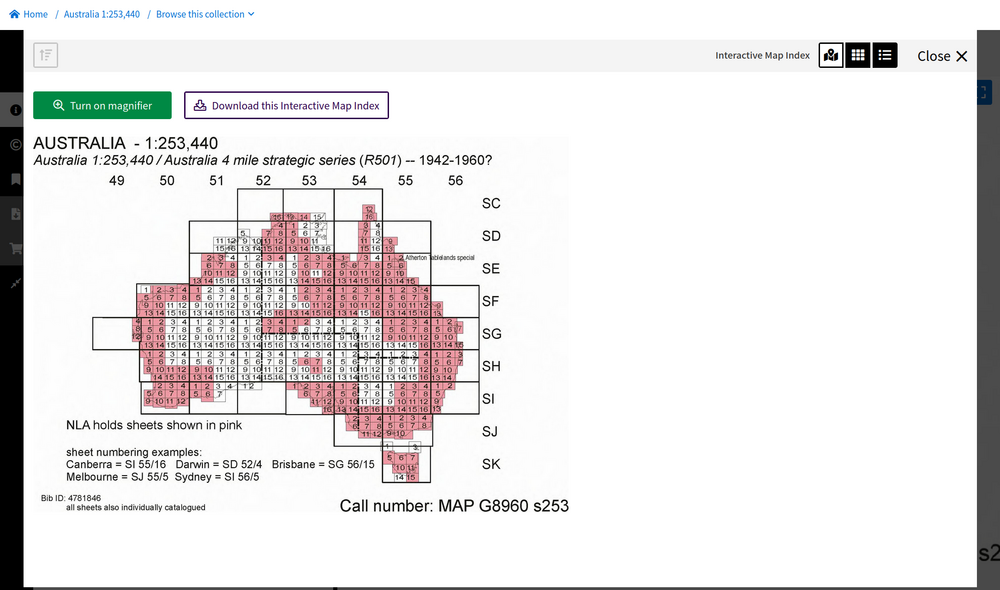
Fig. 6.20 Navigate around a map series by clicking on the index
https://nla.gov.au/nla.obj-234062874#
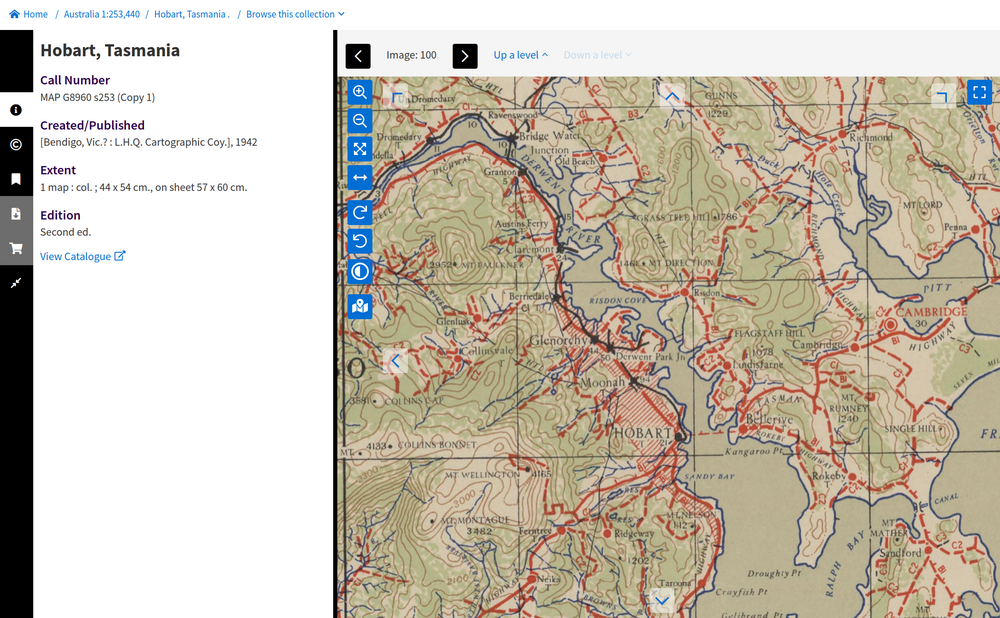
Fig. 6.21 View a digitised map
https://nla.gov.au/nla.obj-234078097#
Finding aids#
See Finding aids in the Trove help documentation for an introduction.
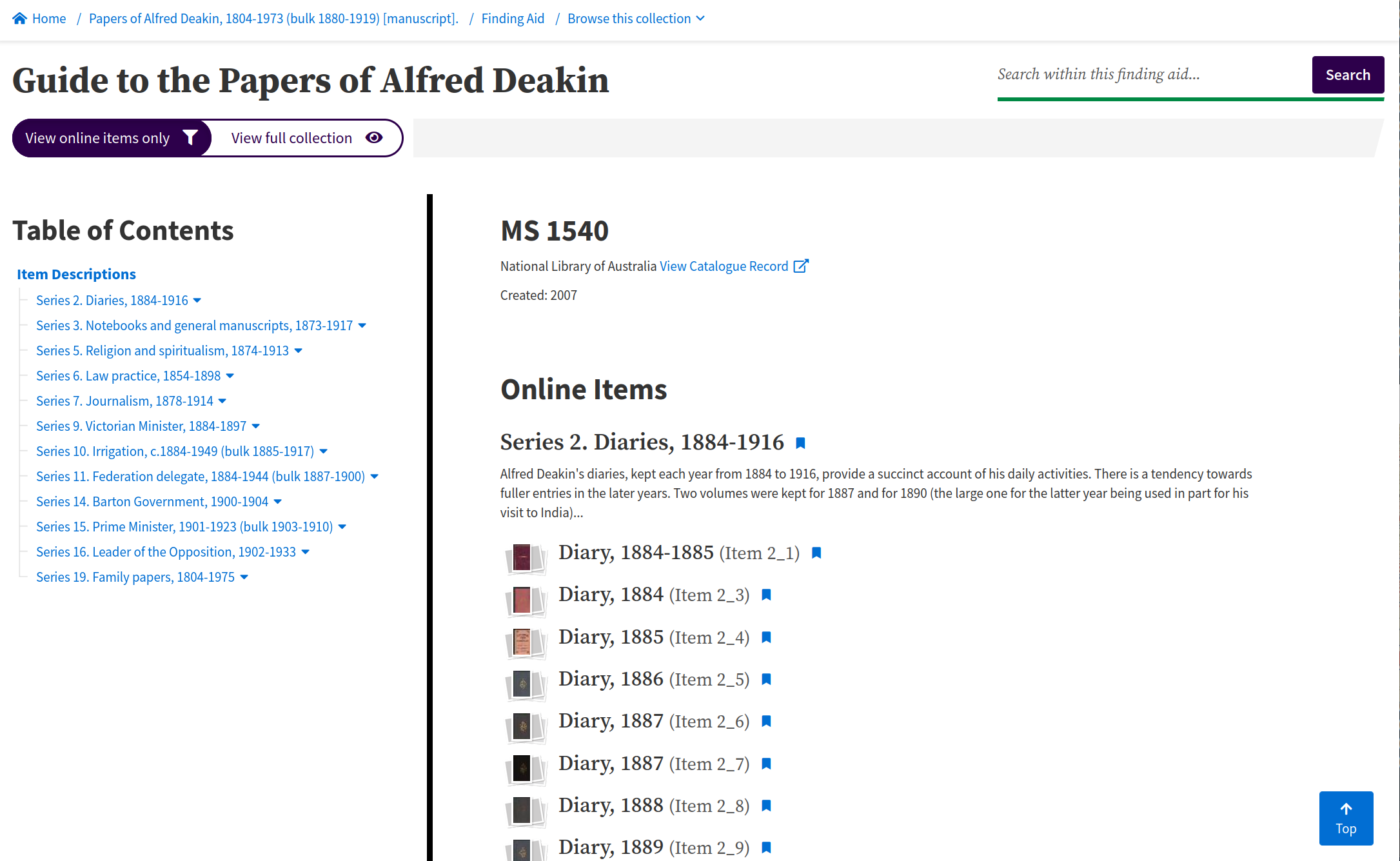
Fig. 6.22 Browse a finding aid for items of interest
https://nla.gov.au/nla.obj-225220821#
If sections of a finding aid are digitised, you can click on the image icon to open a modal window with a list of available items.
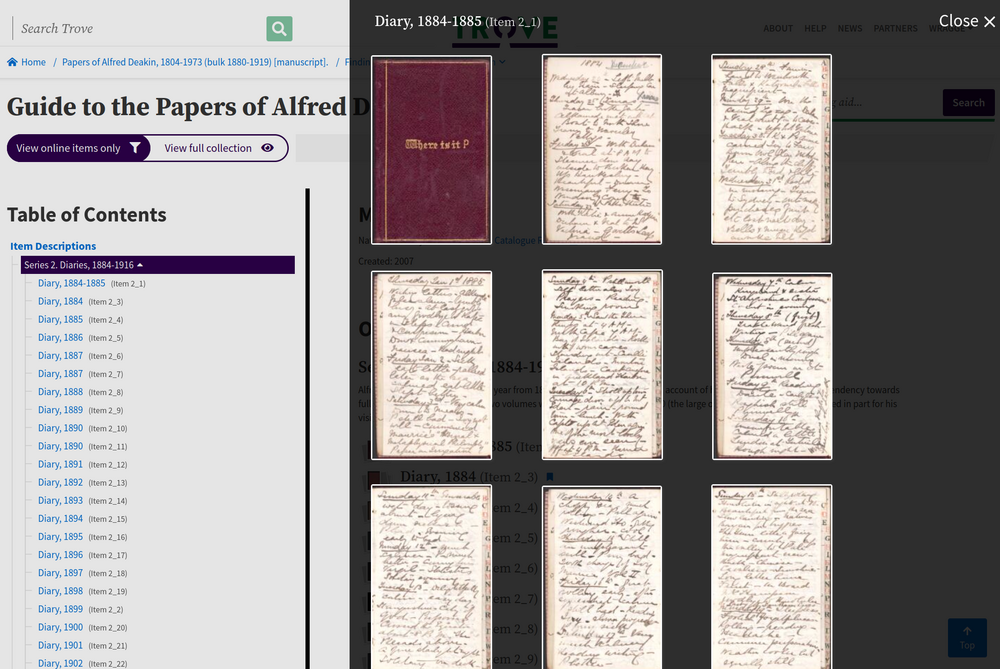
Fig. 6.23 Browse a list of digitised items
https://nla.gov.au/nla.obj-225220821#
Clicking on one of the digitised items in a finding aid opens the item in the digital image viewer (or one of the other digital object viewers).
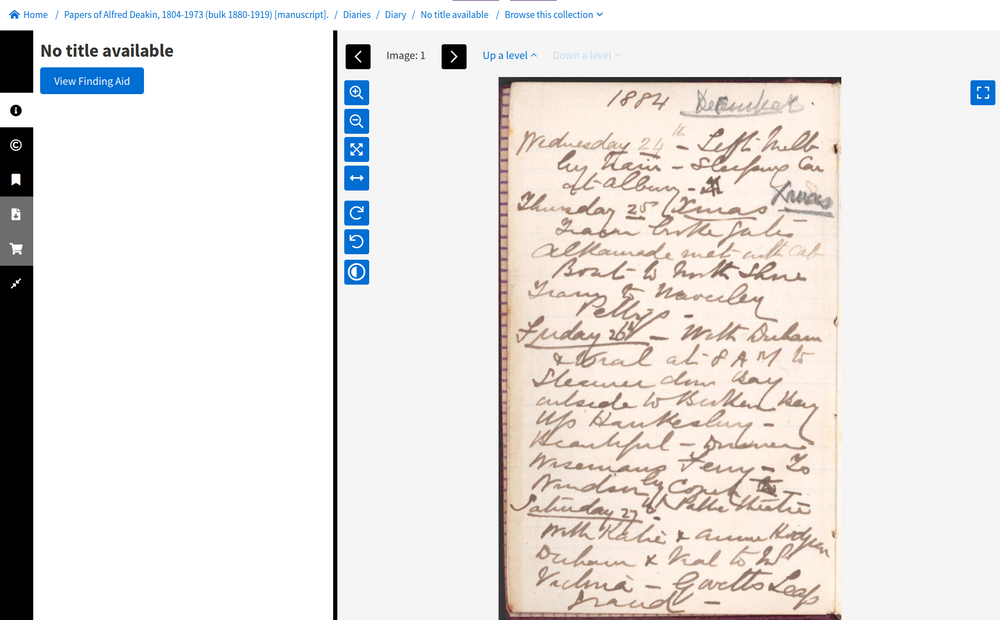
Fig. 6.24 View an item from a finding aid
https://nla.gov.au/nla.obj-225288469#
Audio player#
See Audio player in the Trove help documentation for an introduction.
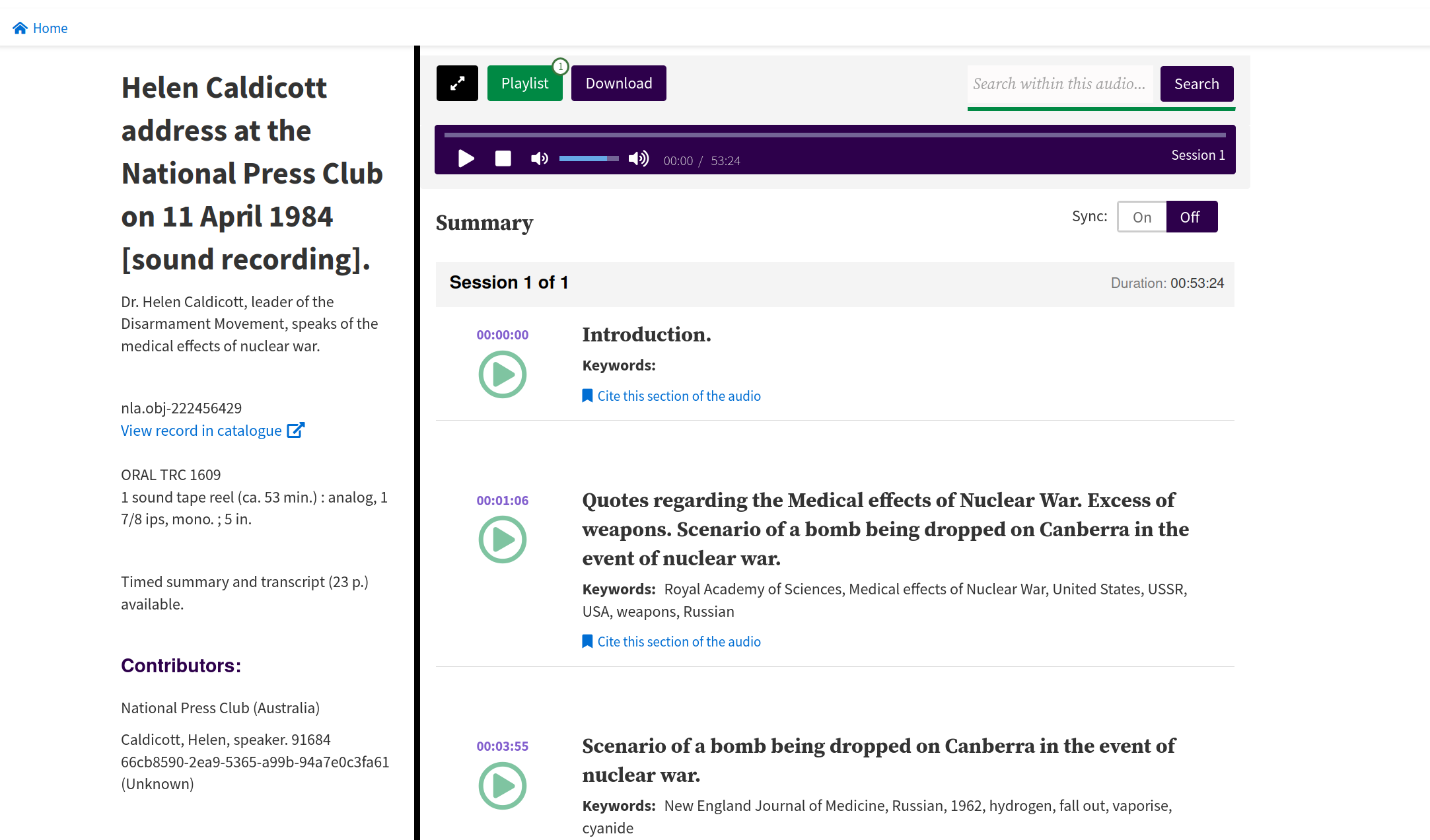
Fig. 6.25 Listen to an audio recording
https://nla.gov.au/nla.obj-222456429#
6.6. Born digital publications#
PDF#
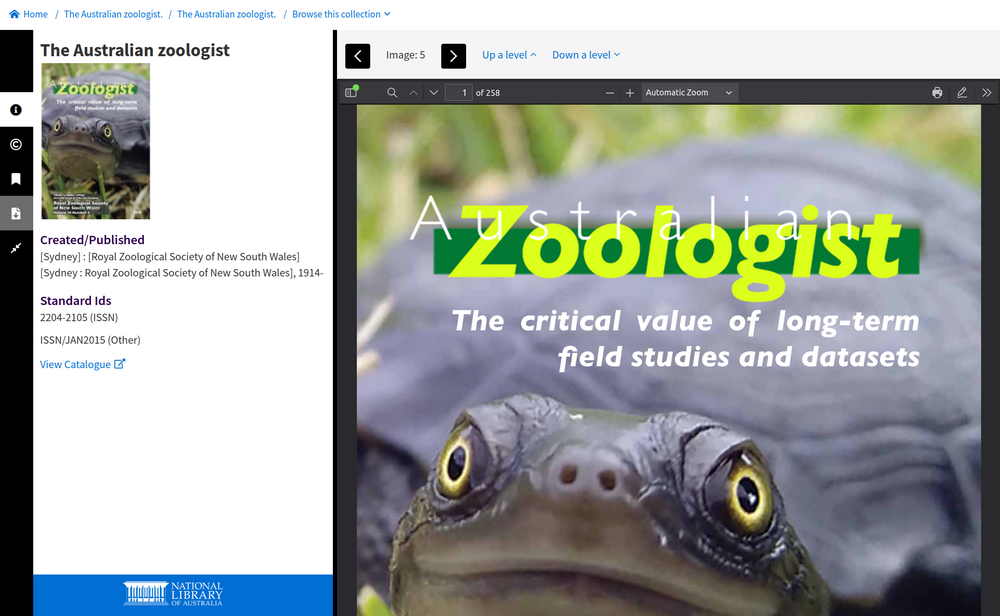
Fig. 6.26 Read a born digital publication in PDF format
https://nla.gov.au/nla.obj-799207608#
epub#
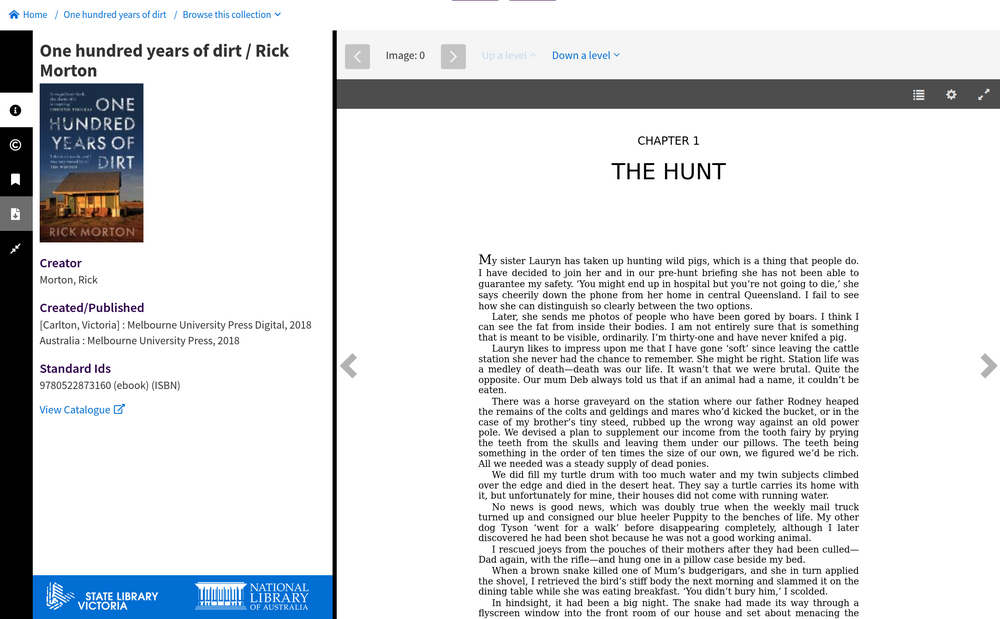
Fig. 6.27 Read a born digital publication in epub format
https://nla.gov.au/nla.obj-1310550566#
6.7. Web archives – search, view, collections#
Search#
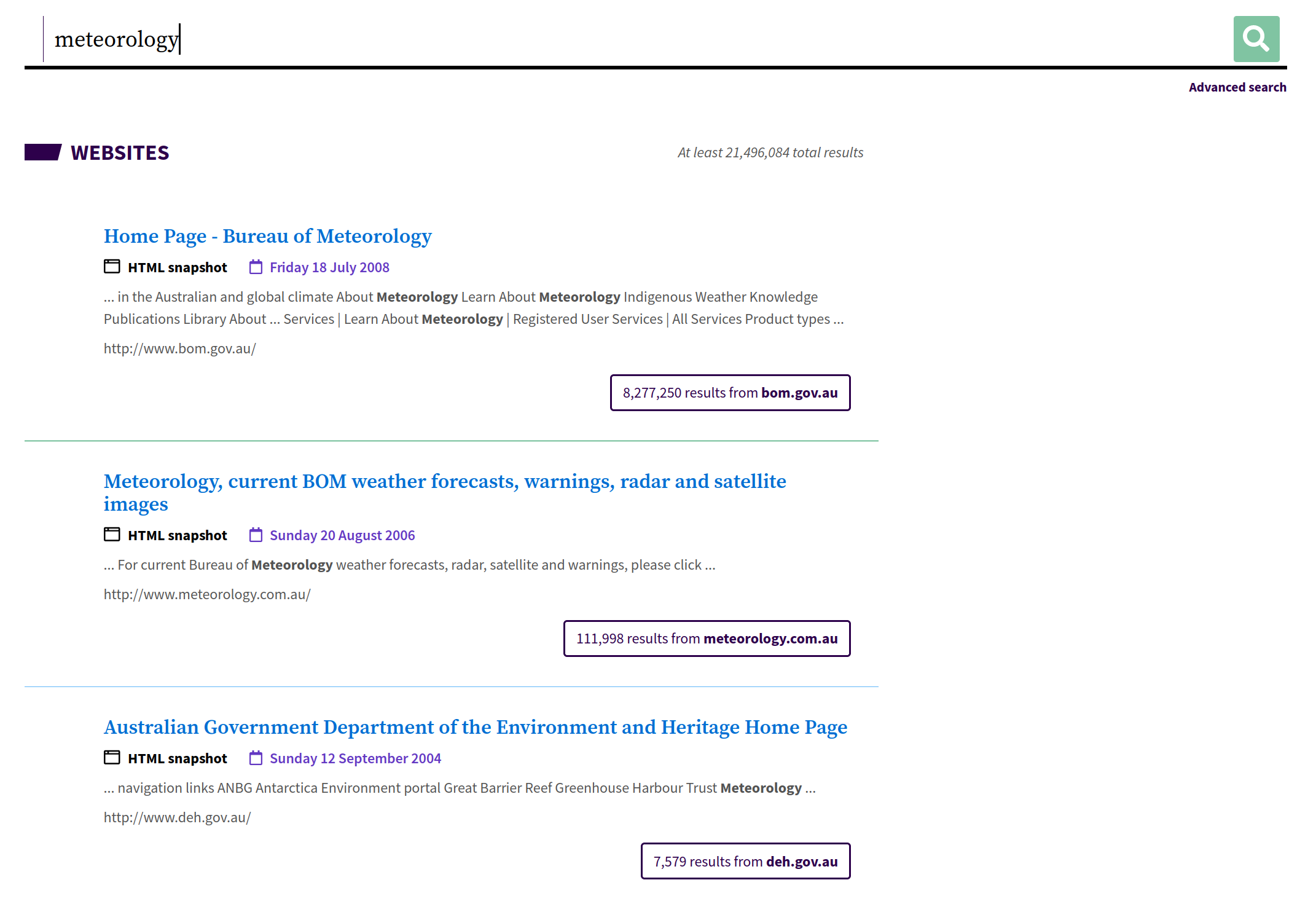
Fig. 6.28 Search for a keyword in the archived websites#
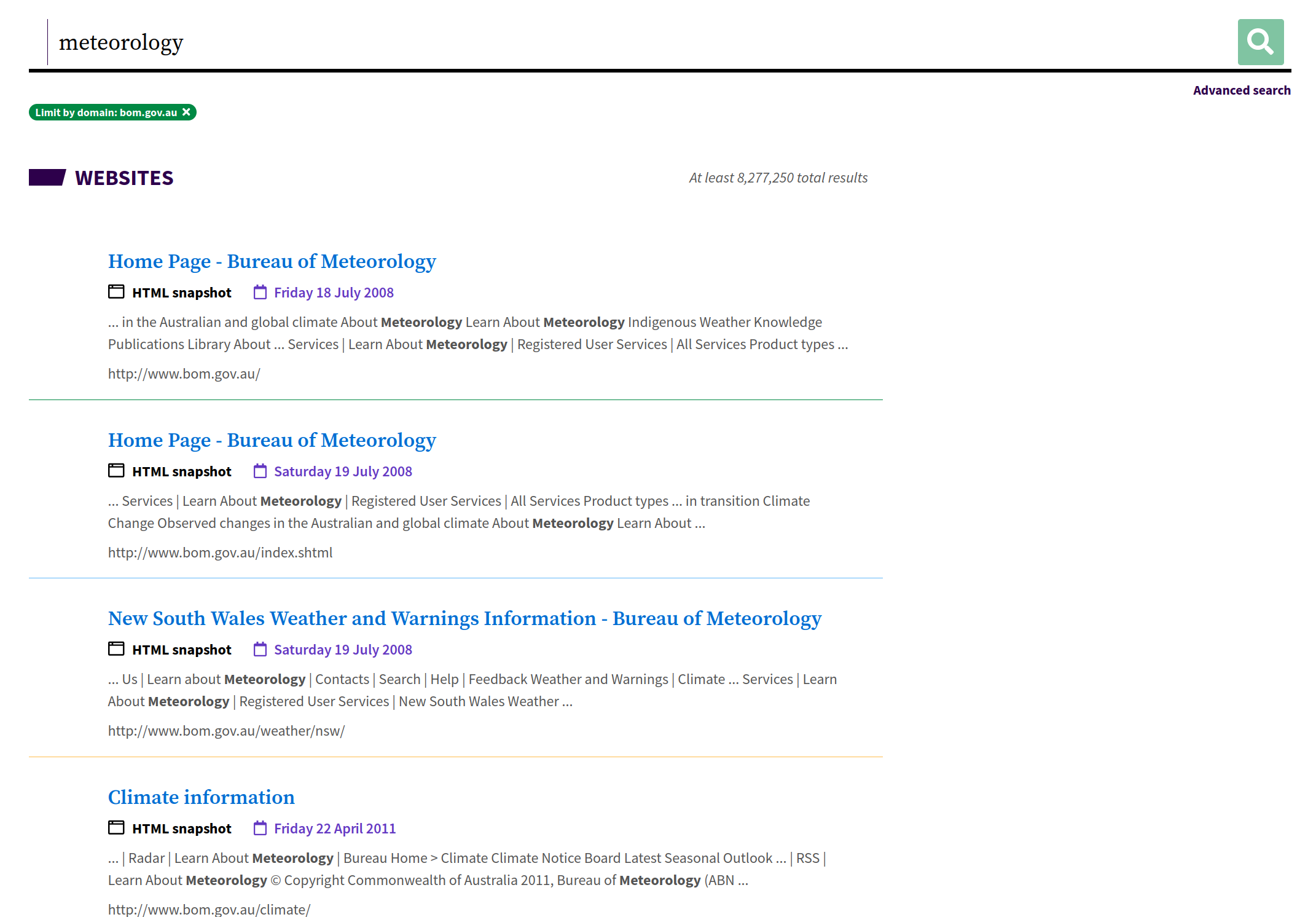
Fig. 6.29 View search results within a specific web domain#
View#
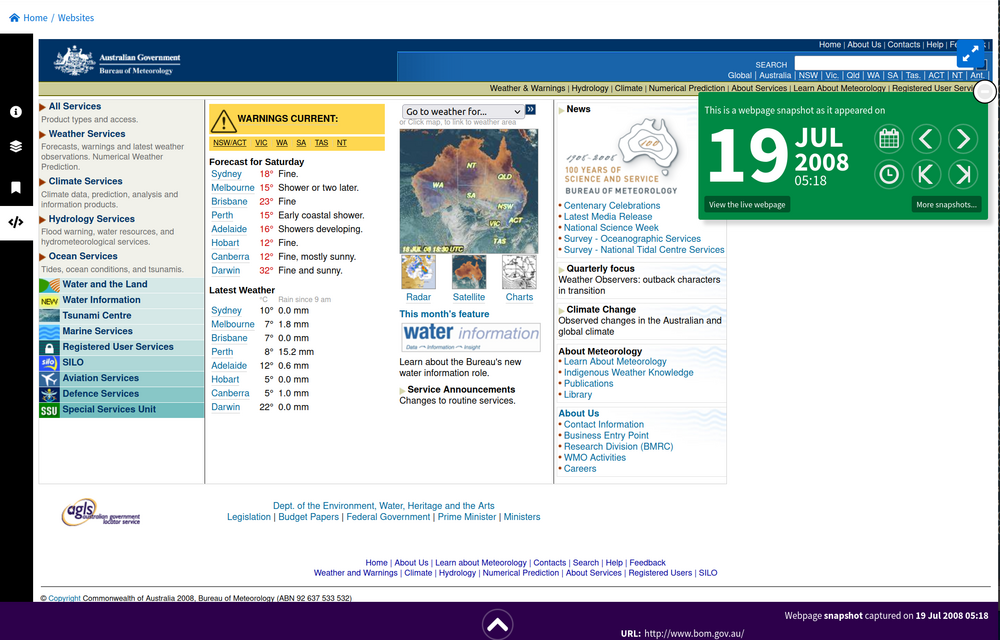
Fig. 6.30 View an archived web page
https://webarchive.nla.gov.au/awa/20080718191843/http://www.bom.gov.au/#
Website title page#
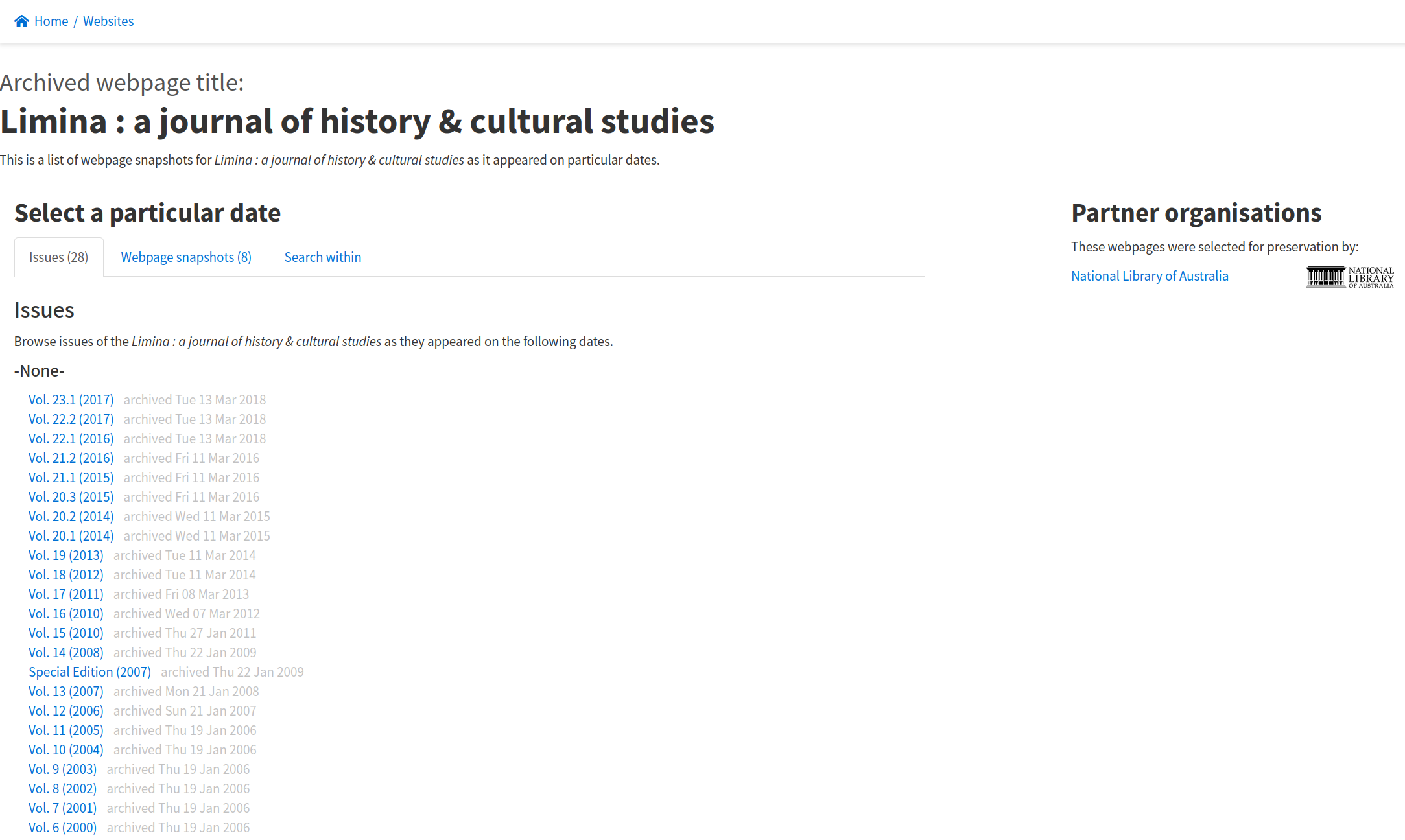
Fig. 6.31 Browse a list of issues or snapshots of a website selected for preservation
https://webarchive.nla.gov.au/tep/11045#
Website collection#
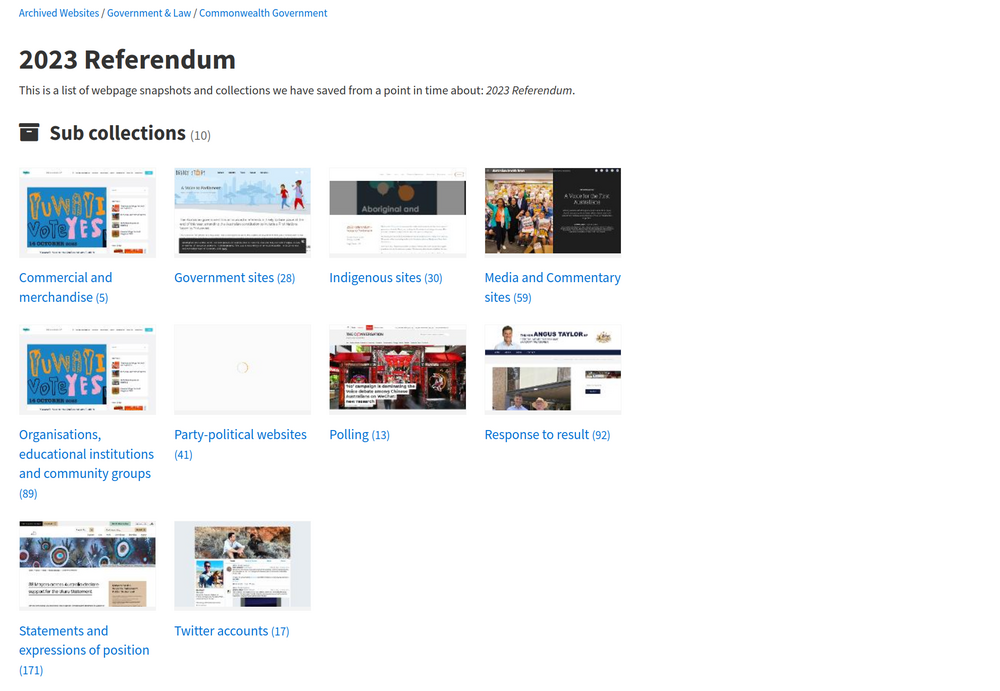
Fig. 6.32 Browse a collection of websites selected for preservation
https://webarchive.nla.gov.au/collection/20575#
6.8. Lists#
View#
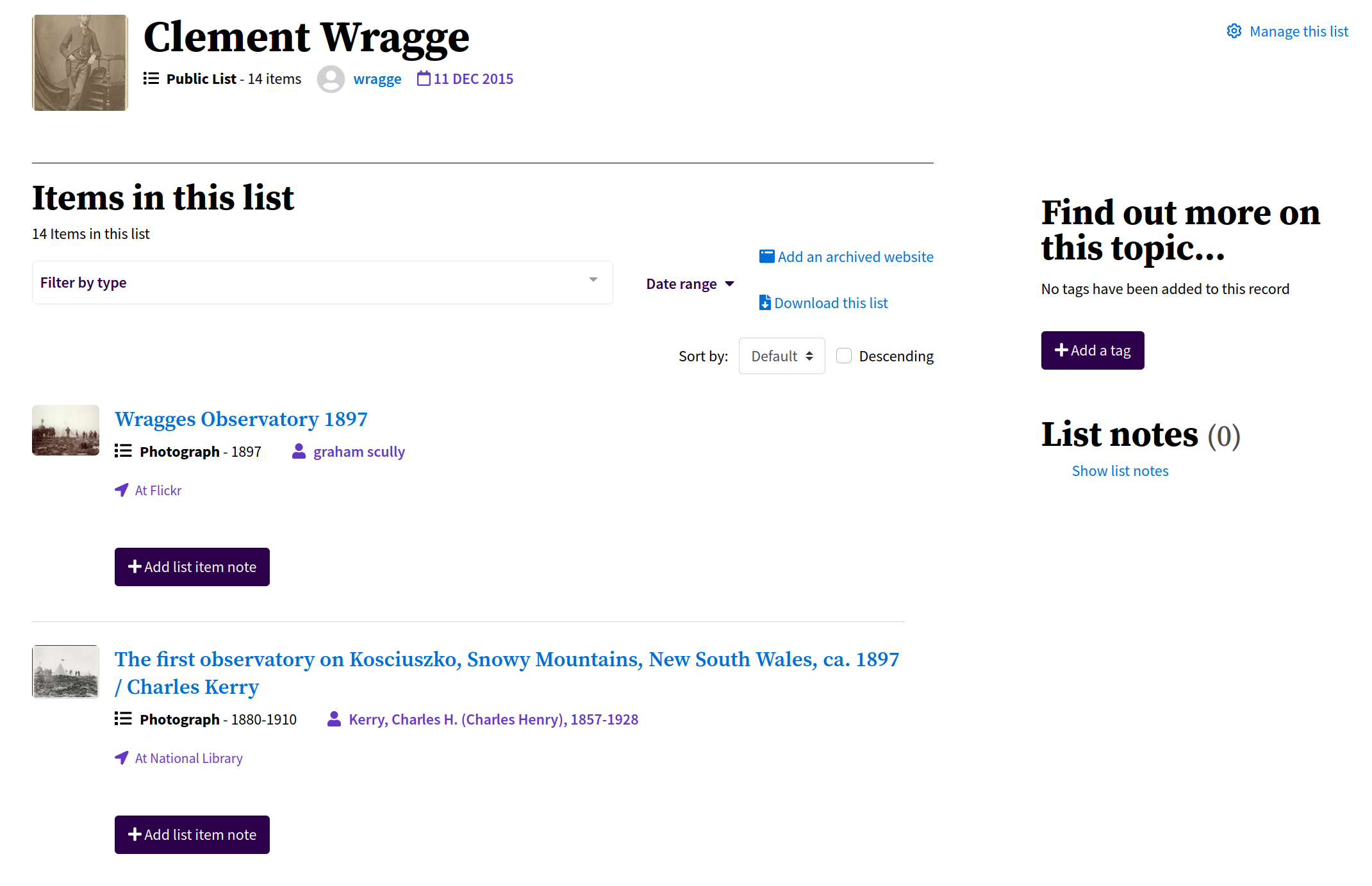
Fig. 6.33 View a Trove list
https://trove.nla.gov.au/list/83777#
Manage#
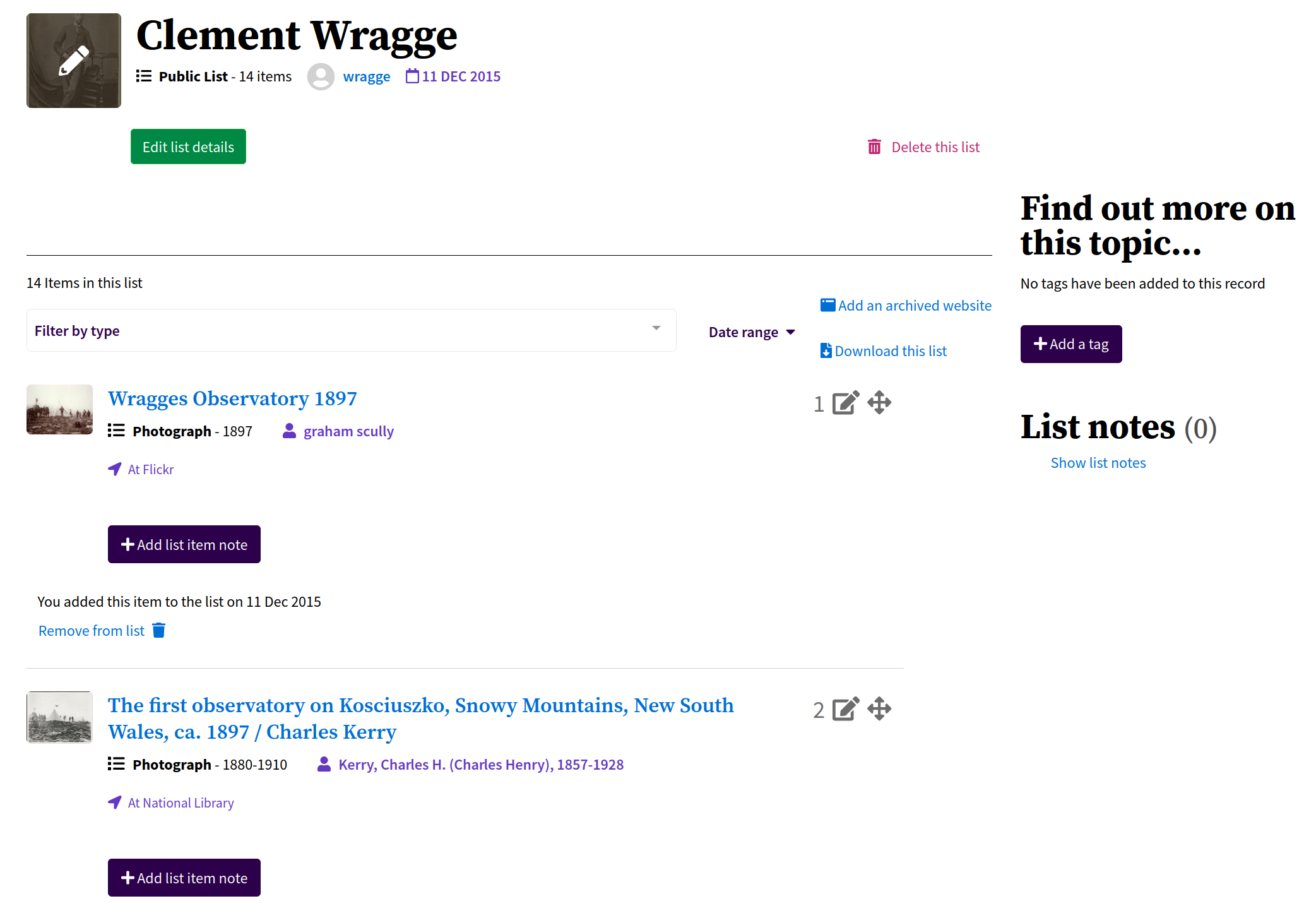
Fig. 6.34 Manage a Trove list#
6.9. User profile#

Fig. 6.35 View your Trove user profile#