
27.3. Tutorials and examples#
This page includes information on tutorials and examples to help you work with text from Trove.
Tutorials#
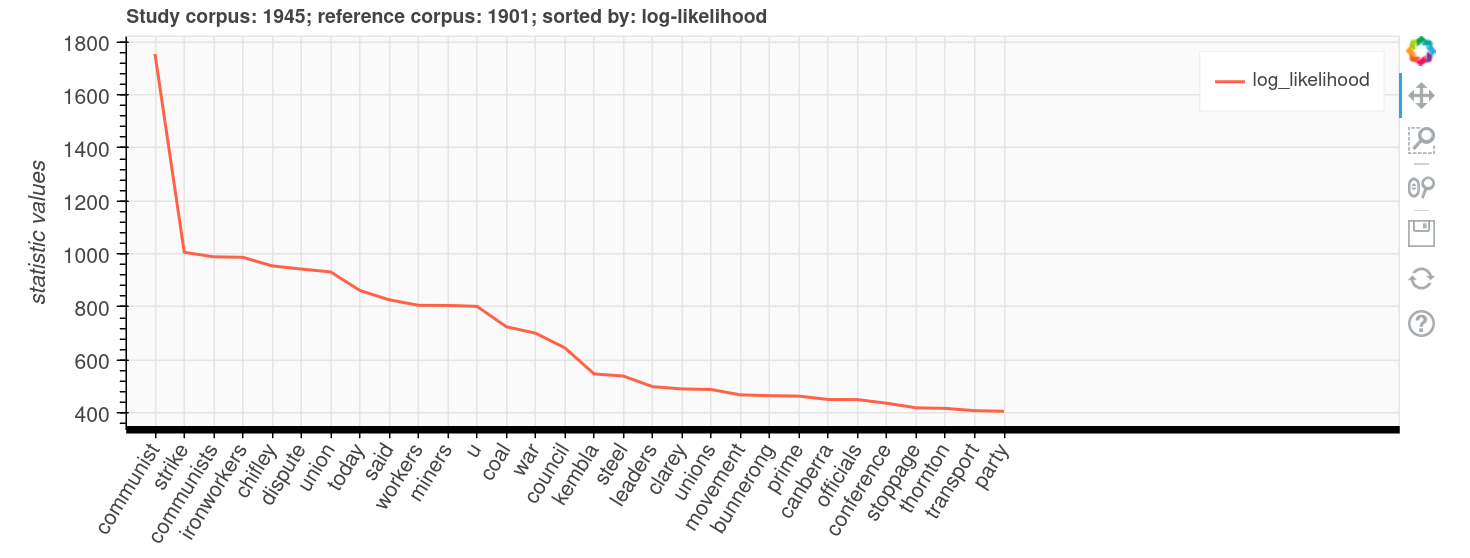
You want to explore differences in language use across a collection of digitised newspaper articles. The Australian Text Analytics Platform provides a Keywords Analysis tool that helps you examine whether particular words are over or under-represented across collections of text. But how do get data from Trove’s newspapers to the keyword analysis tool?
Examples from the GLAM Workbench#
- Exploring text files harvested with the Trove Harvester
This notebook suggests some ways in which you can aggregate and analyse the individual OCRd text files for each article — look at word frequencies; calculate TF-IDF values.
- Finding non-English newspapers in Trove
There are a growing number of non-English newspapers digitised in Trove. However, if you’re only searching using English keywords, you might never know that they’re there. This notebook analyses the language of a sample of articles from each newspaper to create a list of non-English newspapers.
- Counting words and phrases in digitised books
This notebook provides a simple example of extracting word and ngram frequencies from the OCRd text of a digitised book using TextBlob and Wordcloud.
- Recipe generator
In this notebook we use TextBlob to extract nouns, verbs, and sentences from the OCRd text of a 19th century cookery book. We try to clean things up a bit, using regular expressions to discard likely OCR errors. Then we recombine the various parts in random combinations to create delicious recipes for all occasions. Enjoy!
Other examples#
Topic modelling of Trove Books (Adel Rahmani)
Topic modelling of Australian parliamentary press releases (Adel Rahmani)