
25.4. HOW TO: Get text, images, and PDFs using Trove’s download link#
On this page
25.4.1. Background#
You can download text, images, and PDFs from individual digitised items using the Trove web interface. But only the text of periodical articles is available for machine access through the Trove API. This makes it difficult to assemble datasets, or build processing pipelines involving digitised resources.
This page documents a workaround developed by reverse-engineering the download link used by the Trove web interface. You can use it to automate the download of text, images, and PDFs from many digitised resources.
25.4.2. Understanding Trove’s download link#
Trove’s digitised object viewers include a ‘Download’ tab that provides options for downloading the current item.
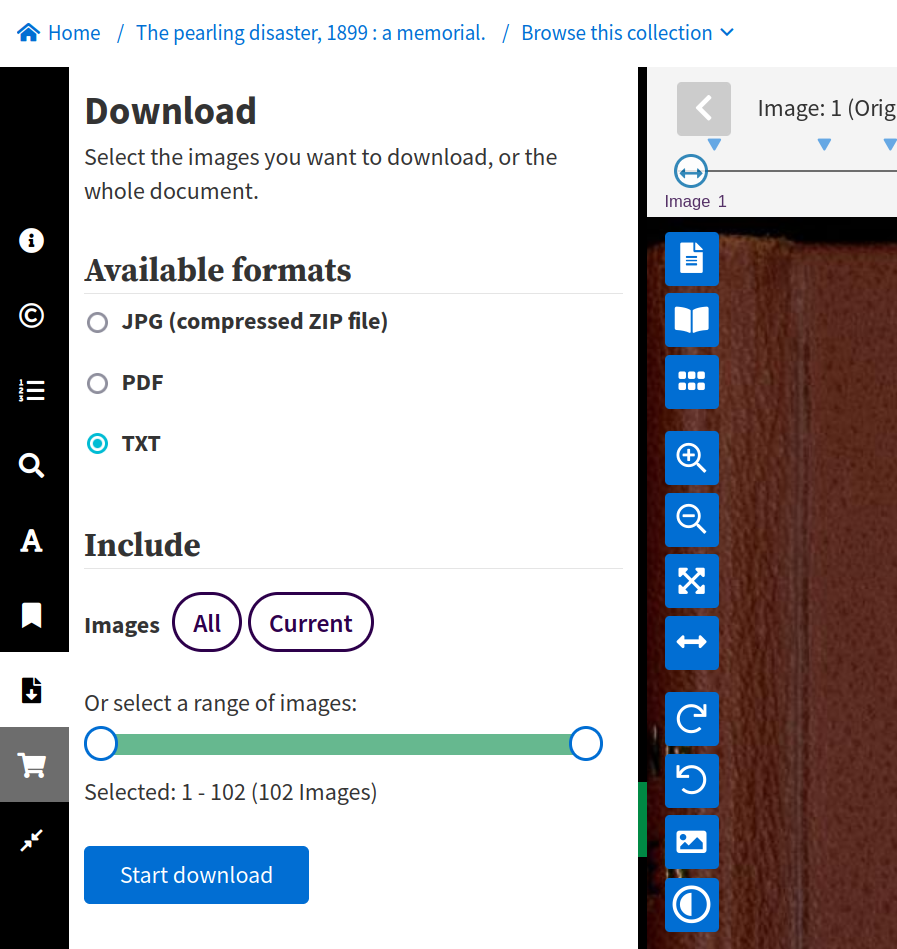
Fig. 25.2 Download options for a digitised book#
When you click on the Start download button, your browser actually fires off a request to Trove that looks like this:
https://nla.gov.au/nla.obj-33685055/download?downloadOption=ocr&firstPage=0&lastPage=101
The url contains a few key parameters.
https://nla.gov.au/nla.obj-[ID]/download?downloadOption=[FORMAT]&firstPage=[FIRST]&lastPage=[LAST]
parameter |
description |
|---|---|
|
the NLA identifier for the current item or collection, for example |
|
the desired format of the download, it can be one of |
|
numbers that define the range of items you want to download – ranges start at |
Note that ‘pages’ in this context actually refers to the number of images in the digitised version, rather than the number of printed pages in the original work. This is because the digitised version will typically include images of book covers and endpapers as well as printed pages.
25.4.3. DIY download links#
Once you understand the structure of the download urls, you can create your own without using the web interface. All you need to know is a resource’s NLA identifier and the number of pages/images it contains.
For example, The gold finder of Australia : how he went, how he fared, how he made his fortune is a pamphlet published in 1853. It’s NLA identifier is nla.obj-248742150 and it has 80 pages. To download all of the OCRd text from this book, you’d insert the identifier and set lastPage to 79 (80 minus 1):
https://nla.gov.au/nla.obj-248742150/download?downloadOption=ocr&firstPage=0&lastPage=79
Or perhaps you’d like the whole pamphlet as a PDF? Just change downloadOption from ocr to pdf:
https://nla.gov.au/nla.obj-248742150/download?downloadOption=pdf&firstPage=0&lastPage=79
Zip files can be big!
By setting downloadOption to zip you can download all the digitised images that make up a resource in a single zip file. But beware! Pages of digitised books or journals can weigh in at a few megabytes each, so zipping them all together can create one, very large file. The gold finder of Australia only has 80 pages, but a zip file containing every page ends up at 282mb! If you want to download all the images from a collection of resources, it’s probably best to take a more patient approach and download each image individually.
25.4.4. Download selected pages#
You don’t have to ask for everything at once. By adjusting the firstPage and lastPage values, you can download a specific range of pages. If you wanted the first ten pages of The gold finder of Australia as zipped images, you’d set firstPage to 0 and lastPage to 9:
https://nla.gov.au/nla.obj-248742150/download?downloadOption=zip&firstPage=0&lastPage=9
To request a single page, set firstPage and lastPage to the same value. For example, if you wanted an image of the cover, you’d set both firstPage and lastPage to 0:
https://nla.gov.au/nla.obj-248742150/download?downloadOption=zip&firstPage=0&lastPage=0
25.4.5. How do you know the number of pages?#
The value of this method lies in the fact that it can be used programatically to download large collections of digitised items without any manual intervention. But to do that you need some way of finding out the number of pages or images in each item so you can set the lastPage value. This information isn’t included in the metadata from the API, and so requires a little extra effort to extract.
The approach varies depending on the type of resource.
If you’re downloading a resource that is made up of pages, such as a book or periodical, you need to:
extract the metadata embedded in the digitised book or journal viewer
get the length of the
pagearray from the metadata
If you’re downloading a collection of images, manuscripts, or maps, you can look for the value of maxNumOfChildDownloads embedded in the HTML of the digitised image viewer. Here’s an example that finds the number of photographs in the collection of B.A.N.Z. Antarctic Research Expedition photographs (nla.obj-141170265).
import requests
import re
obj_id = "nla.obj-141170265"
# Get the page from the digitised image viewer
response = requests.get(f"https://nla.gov.au/{obj_id}")
# Find lines where this variable is referenced
matches = re.findall(r"maxNumOfChildDownloads = (\d+)", response.text)
# This variable can be referenced multiple times - we want to get the highest value
num_items = sorted([int(m) for m in matches])[-1]
print(num_items)
151
25.4.6. Limitations and alternatives#
This method works really well if you want to get all the OCRd text out of books or periodical issues. It’s also handy if you want to download selected pages or images, such as the front covers of periodicals.
However, if your aim is to download all the images from a collection of items then there are two potential problems. The first is that the download link doesn’t always provide images at their highest available resolution. This particularly seems to be the case with manuscript and photographic collections.
The other problem is that the zip files can become very large if you request collections that contain a significant number of pages or images. This makes them slow to download and can cause errors. Of course you also have to add in a step to unzip the zips!
If you’re downloading lots of images or the quality of the images is important to you, I’d suggest you try the alternative approach which involves downloading one at a time. This method is fully documented in HOW TO: Create download links for images using nla.obj identifiers.