
24.2. Accessing data from digitised oral histories#
24.2.1. Identifiers#
Digitised oral histories are uniquely identified by a nla.obj identifier, for example: nla.obj-220905784.
You can find these identifiers in the web interface and in API results. In the web interface, for example, the ‘Listen’ link from this oral history record goes to the url https://nla.gov.au/nla.obj-220905784 which opens the audio player.
If you’re using the API, the digital object url will be in the identifier field of the work or version, with a linktype value equal to fulltext.
"type": "url",
"linktype": "fulltext",
"value": "https://nla.gov.au/nla.obj-220905784"

You can use this identifier to access additional metadata and download transcripts.
24.2.2. Types of data#
There are three types of data from the NLA’s digitised oral histories that you can download:
metadata (available from the Trove API and embedded within the audio player)
text files (timed summaries, full transcripts, or a combination of both)
audio files (available in three bitrates – 48, 128, 256kbps)
A single oral history can be recorded across multiple sessions. There are separate audio files for each session, but summaries and transcripts are combined into a single text file.
24.2.3. Metadata#
Downloadable dataset#
A CSV file containing details of oral histories from the NLA collection (both online and not online) harvested from Trove is available from the GLAM Workbench. You can also explore the data using Datasette.
Search results from the API#
As described elsewhere, you can find details of oral histories from the NLA collection that are available online by searching for "nla.obj" in the music category, with the availability facet set to y, and the format facet set to Sound/Interview, lecture, talk.
Start with this search then add additional keywords or filters to limit the results according to your research needs. For example, you could use the series index to find results from the Hazel de Berg collection.
A complete list of series values is available in this text file.
As with other digitised resources there are some inconsistencies in the description and arrangement of oral histories in Trove. A few things I’ve noticed are:
Different recordings with the same person can be grouped as a single work, for example this work combines recordings from 2010 and 2013.
Some records include links to collection pages, but all of these links seem to return 404 errors. For example, try clicking on the ‘Browse other digitised items’ links in this work record. I’m assuming that all the items within these collections have their own individual work records, so the missing pages can be ignored.
There are some duplicate records (same fulltext urls, slightly different metadata).
To make sure you get all relevant results, I’d recommend harvesting all the version data from the work records and dealing with duplicates at the end. This strategy is described and documented in HOW TO: Harvest data relating to digitised resources.
Additional metadata from audio player#
Trove’s audio player displays some metadata that isn’t included in the API records. This can include:
a descriptive note with the date and place of the recording
a note about the availability of transcripts
roles of the people involved – ie ‘interviewer’ and ‘interviewee’
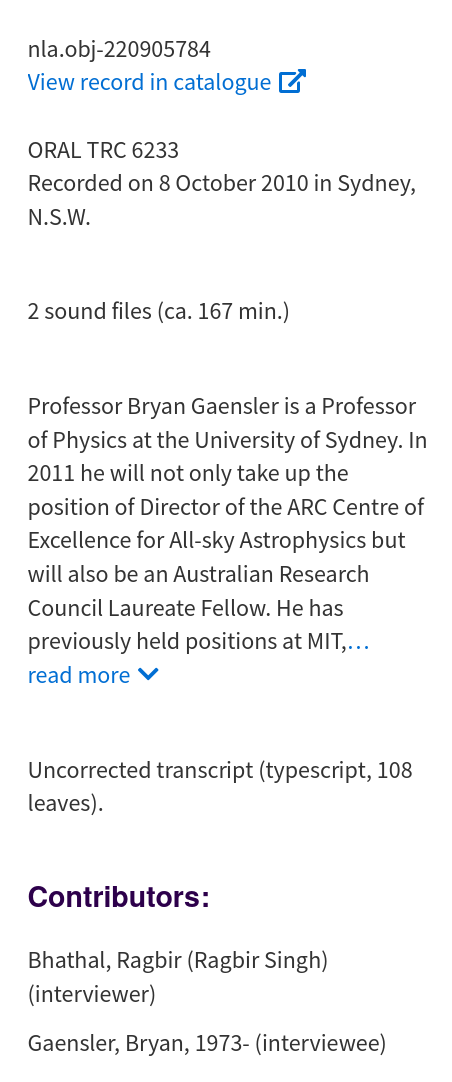
Fig. 24.3 Example of the metadata displayed in Trove’s audio player#
This information could be useful, and you might want to use it to enrich the records harvested from the API. Some example code that you can use to scrape this metadata using the digital object url of an oral history record is included in HOW TO: Scrape metadata from the Trove audio player.
Details of available downloads#
When you click on the ‘Download’ button in the audio player, a window pops up with links to download the summary/transcript and any audio files. The contents of this pop-up are generated from a Javascript file. It’s possible to access this Javascript file directly and extract details about available downloads.
The Javascript file includes the following fields:
anySummary– indicates if a summary is available, set to eithertrueorfalseanyTranscript– indicates if a transcript is available, set to eithertrueorfalsesessions– a list of session details include timed summariessessionFiles– a list of audio files available from each session
Here’s an example of the file data, showing that the audio from each session is available for download at three different bitrates (indicated by the data_rate field):
"sessionFiles" : [ {
"label" : "Session 1",
"files" : [ {
"use" : "derivative",
"size" : 26825472,
"mimetype" : "audio/mpeg",
"access" : "Unrestricted",
"href" : "https://nla.gov.au/tarkine/listen/download/nla.obj-219744824?copyRole=l1",
"downloadmpeg" : "https://nla.gov.au/tarkine/listen/download/nla.obj-219744824?copyRole=l1",
"streaming" : "rtmpt://mp3-streaming.nla.gov.au:80/audiodelivery/mp3:efde93481c560578b4a5ed2f1e0deeaa4a715cd2",
"analogdigitalflag" : "FileDigital",
"audio_data_encoding" : null,
"data_rate" : "48",
"sampling_frequency" : "0",
"duration" : 4470
}, {
"use" : "derivative",
"size" : 71534976,
"mimetype" : "audio/mpeg",
"access" : "Unrestricted",
"href" : "https://nla.gov.au/tarkine/listen/download/nla.obj-219744824?copyRole=l2",
"downloadmpeg" : "https://nla.gov.au/tarkine/listen/download/nla.obj-219744824?copyRole=l2",
"streaming" : "rtmpt://mp3-streaming.nla.gov.au:80/audiodelivery/mp3:e26aa37f785a1143853cb902a43bea79ef10f3cc",
"analogdigitalflag" : "FileDigital",
"audio_data_encoding" : null,
"data_rate" : "128",
"sampling_frequency" : "0",
"duration" : 4470
}, {
"use" : "derivative",
"size" : 143069952,
"mimetype" : "audio/mpeg",
"access" : "Unrestricted",
"href" : "https://nla.gov.au/tarkine/listen/download/nla.obj-219744824?copyRole=l3",
"downloadmpeg" : "https://nla.gov.au/tarkine/listen/download/nla.obj-219744824?copyRole=l3",
"streaming" : "rtmpt://mp3-streaming.nla.gov.au:80/audiodelivery/mp3:de322b949c6ca359d48e2f285deeda2b4fb708d8",
"analogdigitalflag" : "FileDigital",
"audio_data_encoding" : null,
"data_rate" : "256",
"sampling_frequency" : "0",
"duration" : 4470
} ]
}
View the complete Javascript file
Each session’s audio file has it’s own unique nla.obj identifier. You can find it in the urls of the href and downloadmpeg fields. In the example above, it’s nla.obj-219744824. As described below, you can use these identifiers to automate the download of audio files from a list of oral history records.
The urls of these Javascript files have the following pattern:
https://nla.gov.au/tarkine/listen/transcript/[NLA.OBJ ID].js
In this case, you use the nla.obj identifier of the oral history record, for example:
https://nla.gov.au/tarkine/listen/transcript/nla.obj-219744824.js
The actual data is wrapped in a Javascript function. You can extract it using a regular expression. For example, to download and extract the data for the oral history record with the identifier nla.obj-222301677, you can use:
import json
import re
import requests
# nla.obj of an oral history record
id = "nla.obj-222301677"
# Request the JS file
response = requests.get(f"https://nla.gov.au/tarkine/listen/transcript/{id}.js")
# Extract the JSON data from the JS function using regex
data = re.search(r"define\((\{.*)\)", response.text, re.DOTALL).group(1)
# Load the JSON data
json_data = json.loads(data)
You can then extract some useful information from the data:
# Does it have a summary?
print(f"Has summary: {json_data['anySummary']}")
# Does it have a transcript?
print(f"Has transcript: {json_data['anyTranscript']}")
# How many sessions are there?
print(f"Sessions: {len(json_data['sessions'])}\n")
duration = 0
# Loop all the files/bitrates
for session in json_data["sessionFiles"]:
for file in session["files"]:
# Get the download link
print(file["href"])
duration += file["duration"]
print(f"\nTotal duration: {duration} seconds")
Has summary: False
Has transcript: True
Sessions: 5
https://nla.gov.au/tarkine/listen/download/nla.obj-222301689?copyRole=l1
https://nla.gov.au/tarkine/listen/download/nla.obj-222301689?copyRole=l2
https://nla.gov.au/tarkine/listen/download/nla.obj-222301689?copyRole=l3
https://nla.gov.au/tarkine/listen/download/nla.obj-222302002?copyRole=l1
https://nla.gov.au/tarkine/listen/download/nla.obj-222302002?copyRole=l2
https://nla.gov.au/tarkine/listen/download/nla.obj-222302002?copyRole=l3
https://nla.gov.au/tarkine/listen/download/nla.obj-222302323?copyRole=l1
https://nla.gov.au/tarkine/listen/download/nla.obj-222302323?copyRole=l2
https://nla.gov.au/tarkine/listen/download/nla.obj-222302323?copyRole=l3
https://nla.gov.au/tarkine/listen/download/nla.obj-222302643?copyRole=l1
https://nla.gov.au/tarkine/listen/download/nla.obj-222302643?copyRole=l2
https://nla.gov.au/tarkine/listen/download/nla.obj-222302643?copyRole=l3
https://nla.gov.au/tarkine/listen/download/nla.obj-222302969?copyRole=l1
https://nla.gov.au/tarkine/listen/download/nla.obj-222302969?copyRole=l2
https://nla.gov.au/tarkine/listen/download/nla.obj-222302969?copyRole=l3
Total duration: 78024 seconds
24.2.4. Transcripts and summaries#
Each oral history record has a single text file combining summaries and transcripts for every session of the interview. The urls used to download this file have the pattern:
https://nla.gov.au/tarkine/listen/download/transcript/[NLA.OBJ ID]
In this case, you use the nla.obj identifier of the oral history record, for example:
https://nla.gov.au/tarkine/listen/download/transcript/nla.obj-219744824
The text files come in different formats depending on whether a summary, a transcript, or both, are available. Here are some examples:
24.2.5. Audio files#
Each audio file has it’s own nla.obj identifier. Using this identifier, you can download the file at a variety of bitrates.
The url pattern to use when downloading audio files is:
https://nla.gov.au/tarkine/listen/download/[NLA.OBJ ID]?copyRole=l[BITRATE LEVEL]
The bitrate level is a value between 1 and 3:
Level 1: 48kbps
Level 2: 128kbps
Level 3: 256kbps
So to download the audio file with an identifier equal to nla.obj-219744824 at a bitrate of 48kbps, you’d use this url:
https://nla.gov.au/tarkine/listen/download/nla.obj-219744824?copyRole=l1
To get the same file at a bitrate of 256kbps you just change the final 1 to 3.
If you don’t have the audio file identifiers, you can extract them from the Javascript file that contains details of available downloads.